Transformer 20 步可视化学习笔记
本文参考 Transformer Explainer 的交互式讲解,按它的 20 个步骤整理一篇中文学习笔记。这个网站用 GPT-2 small 作为示例模型,把文本生成过程可视化成从输入 token 到输出概率的完整流水线。
先记住一句话:GPT 类 Transformer 的核心任务是下一个 token 预测。给定提示词:
Data visualization empowers users to
模型要回答的问题是:
下一个最可能出现的 token 是什么?
为了回答这个问题,Transformer 会经历:分词、嵌入、位置编码、多层 Transformer Block、自注意力、MLP、logits、概率分布、采样策略等步骤。
本文所有步骤截图均截取自 Transformer Explainer,该项目由 Georgia Tech Polo Club 团队开发。截图用于个人学习笔记,建议结合原网站交互查看。
What is Transformer:Transformer 是什么
Transformer 是现代大语言模型最常用的基础架构。GPT、Llama、Gemini 这类文本生成模型,核心都可以理解为 Transformer 架构的扩展版本。
它最重要的能力不是“背答案”,而是从大量文本中学会语言模式,然后在推理时根据上下文预测下一个 token。这个预测会反复进行:预测一个 token,把它接到原文本后面,再继续预测下一个。
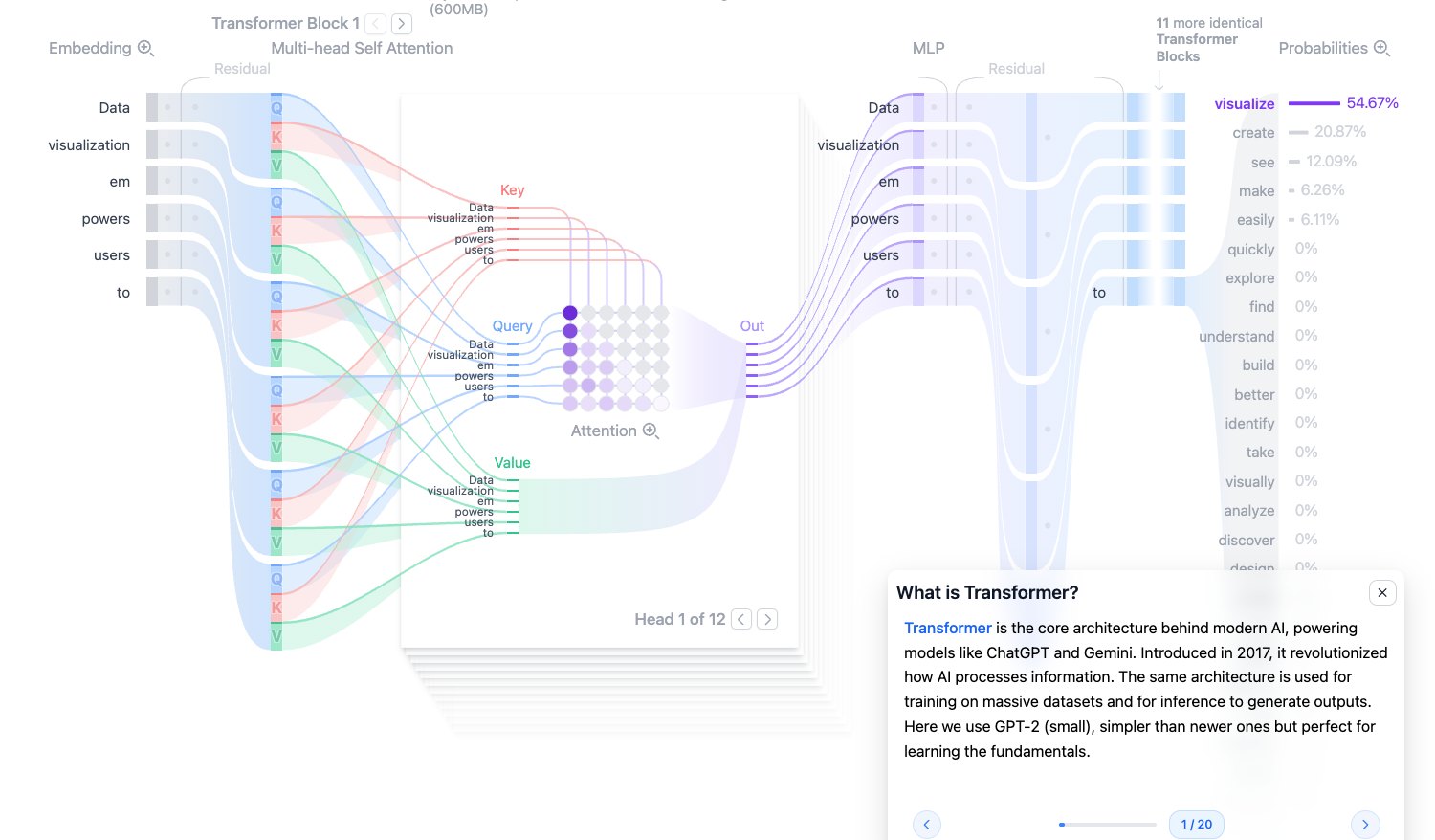
图源:Transformer Explainer,https://poloclub.github.io/transformer-explainer/
How Transformers Work:文本生成的本质
Transformer 生成文本时并不是一次性写完整段话,而是逐步生成。每一步都在做同一个任务:根据已有上下文,预测下一个 token 的概率分布。
例如当前输入是:
Data visualization empowers users to
模型可能认为下一个 token 是 visualize 的概率最高,也可能给 create、see、make 等 token 分配较高概率。最终输出哪个 token,还会受到 temperature、top-k、top-p 等采样参数影响。
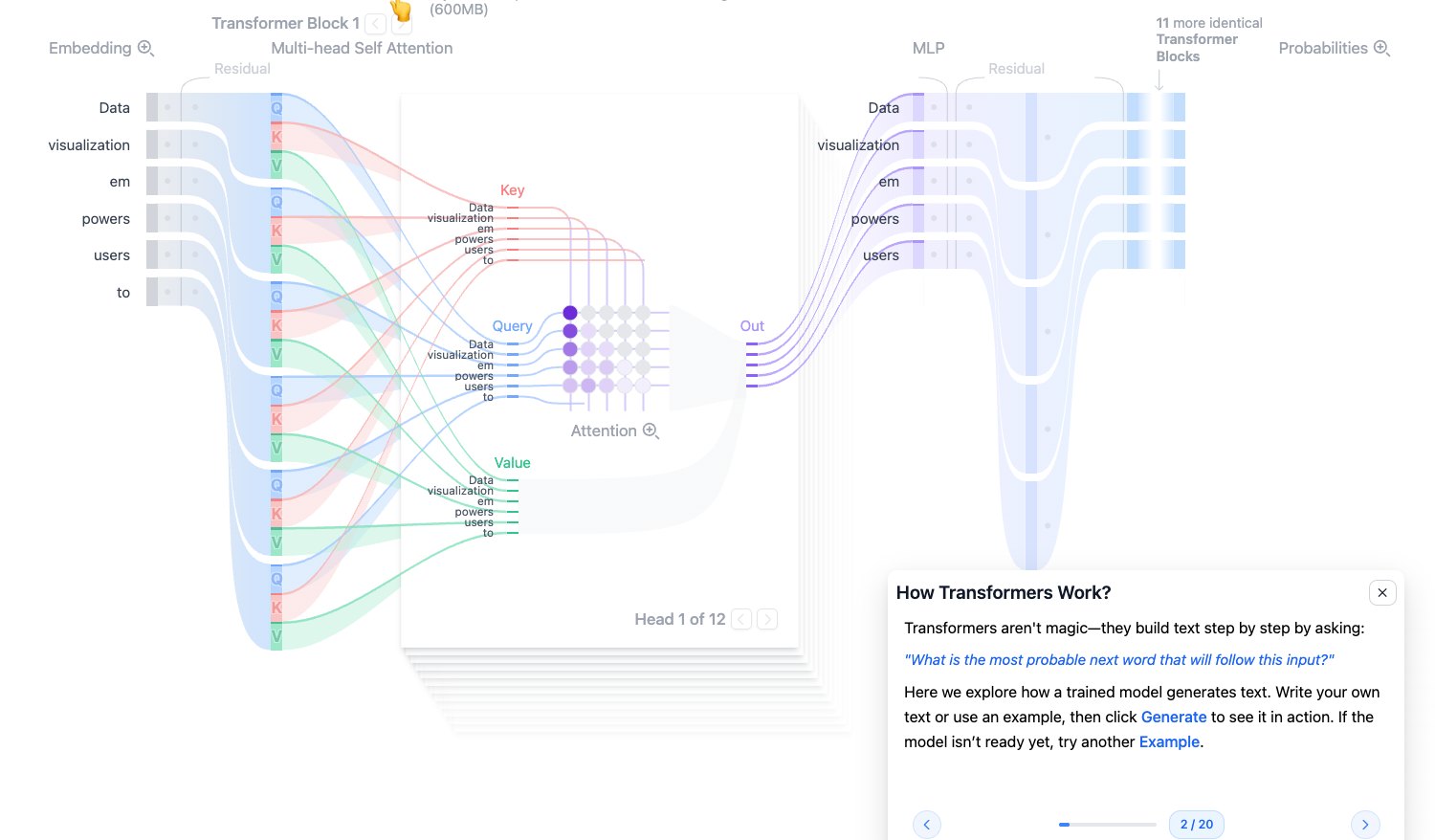
图源:Transformer Explainer
Transformer Architecture:整体架构
一个文本生成 Transformer 可以拆成三大部分:
- Embedding:把人类文本变成模型能处理的向量。
- Transformer Blocks:反复加工每个 token 的表示,核心包括 Self-Attention 和 MLP。
- Output Probabilities:把最终向量变成词表中每个 token 的概率。
从宏观上看,信息流是:
文本输入 -> token -> embedding -> 多层 Transformer Block -> logits -> 概率 -> 采样下一个 token
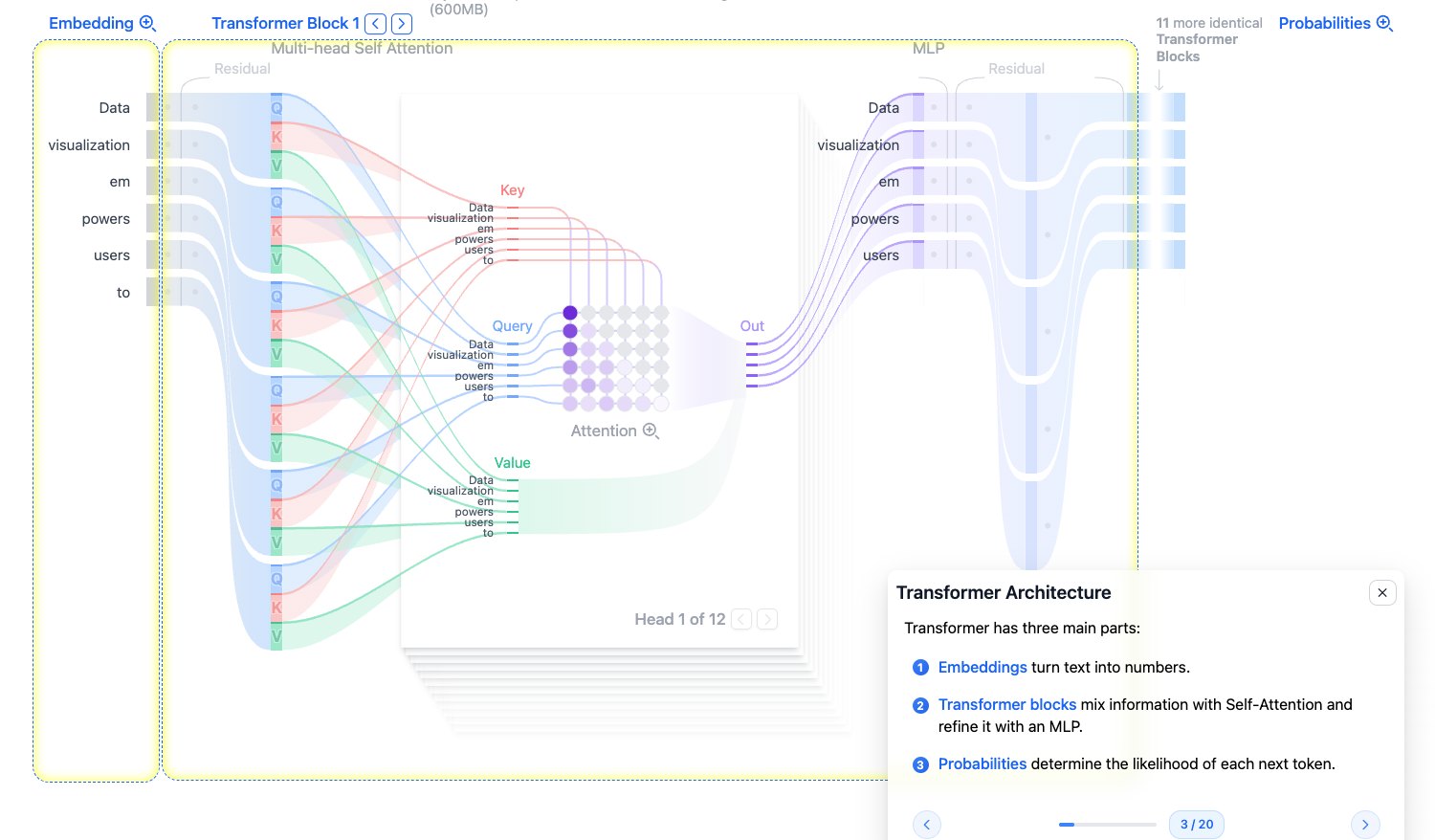
图源:Transformer Explainer
Embedding:把文本变成向量
模型不能直接理解字符串。Embedding 的作用是把每个 token 转成一串数字,也就是向量。这个向量不是随便编码的,而是在训练过程中学出来的。
如果两个 token 经常出现在相似语境中,它们的 embedding 往往会在高维空间中更接近。可以把 embedding 理解成模型内部的“词义坐标”。
GPT-2 small 的隐藏维度是 768,所以每个 token 会被表示成一个 768 维向量。
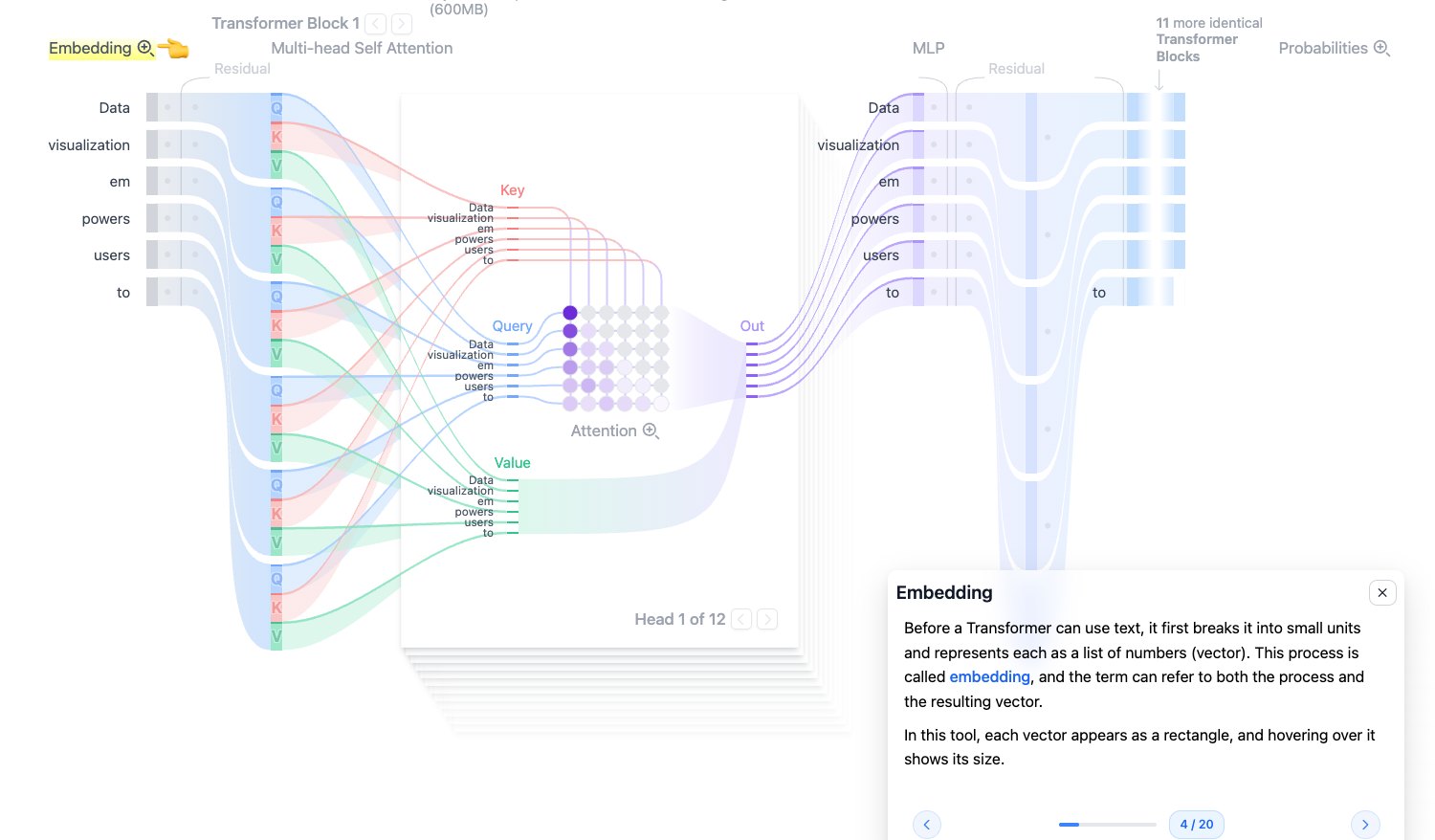
图源:Transformer Explainer
Token Embedding:分词与 token 查表
Tokenization 会把输入文本切成 token。token 可以是完整单词,也可以是子词。例如示例里的 empowers 被切成了 em 和 powers。
每个 token 都有一个唯一 ID。GPT-2 的词表大小是 50,257,所以 token embedding 矩阵大致是:
$$ 50257 \times 768 $$模型拿到 token ID 后,会去这个大矩阵里查出对应的 768 维向量。
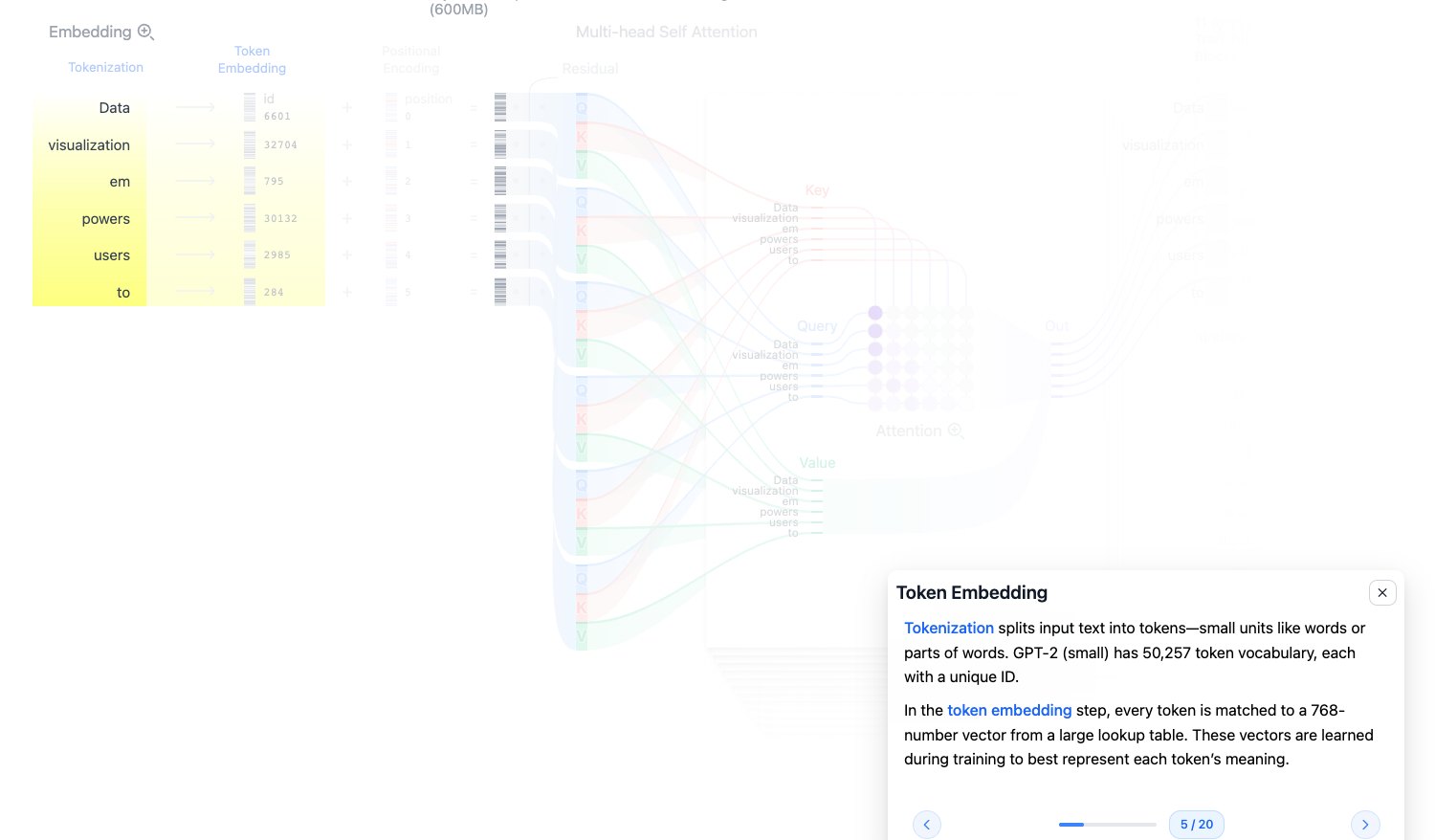
图源:Transformer Explainer
Positional Encoding:注入位置信息
Self-Attention 本身不天然知道顺序。如果只给模型一组 token 向量,它并不知道哪个 token 在前、哪个在后。
所以需要位置编码。GPT-2 使用可学习的位置 embedding,把 token 的语义向量和位置向量相加:
$$ x_i = \text{TokenEmbedding}_i + \text{PositionEmbedding}_i $$这样模型既知道“这个 token 是什么”,也知道“它在第几个位置”。
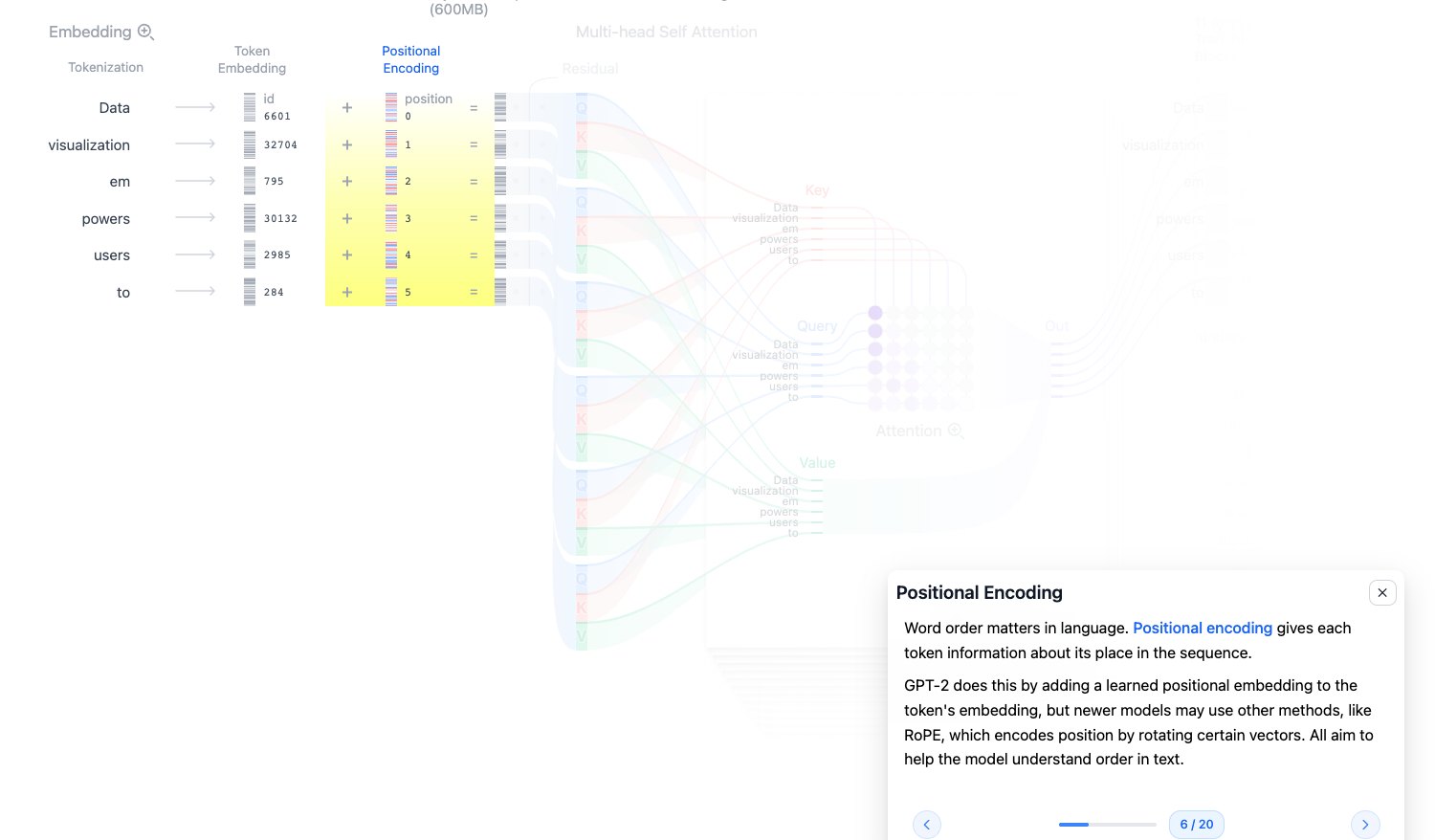
图源:Transformer Explainer
Repetitive Transformer Blocks:重复堆叠的 Transformer Block
Embedding 只是输入表示,还不是充分理解后的语义表示。真正的上下文建模发生在 Transformer Block 中。
GPT-2 small 有 12 个 Transformer Block。每个 block 大致包含:
- Multi-Head Self-Attention:让 token 之间交换信息。
- MLP:对每个 token 的表示做非线性加工。
- Residual、LayerNorm、Dropout:让训练更稳定,泛化更好。
多层堆叠的意义是:底层更偏局部和词法信息,高层更容易形成复杂语义和任务相关表示。
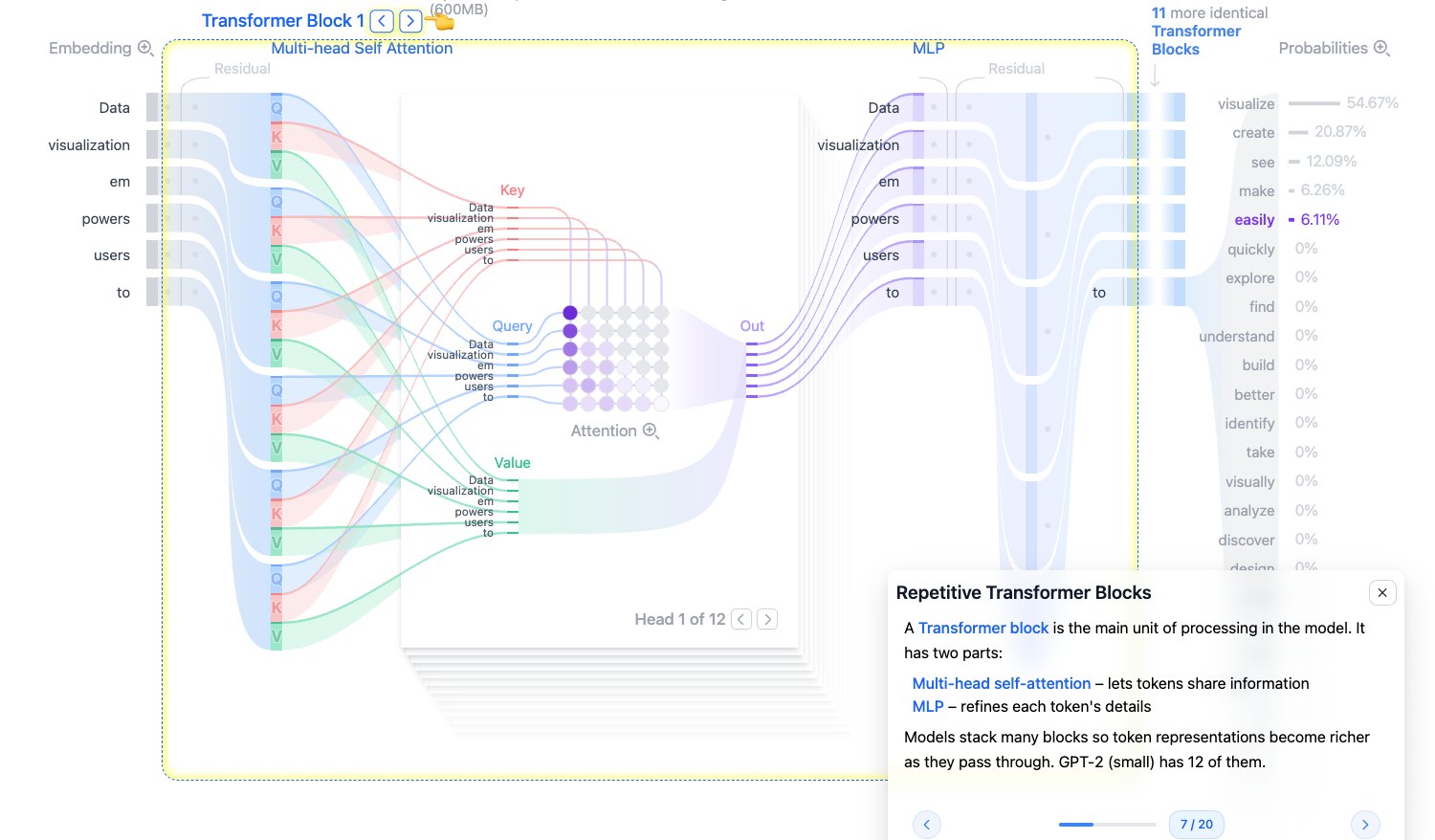
图源:Transformer Explainer
Multi-Head Self Attention:多头自注意力
Self-Attention 的目标是让每个 token 根据上下文更新自己。比如 to 这个 token 在不同句子里含义不同,它需要“看”前面的 Data visualization empowers users,才能形成更准确的表示。
Multi-Head 的含义是:模型不是只用一种注意力视角,而是并行使用多个 head。GPT-2 small 有 12 个 attention heads。不同 head 可以学习不同关系,例如语法关系、短距离搭配、长距离语义依赖等。
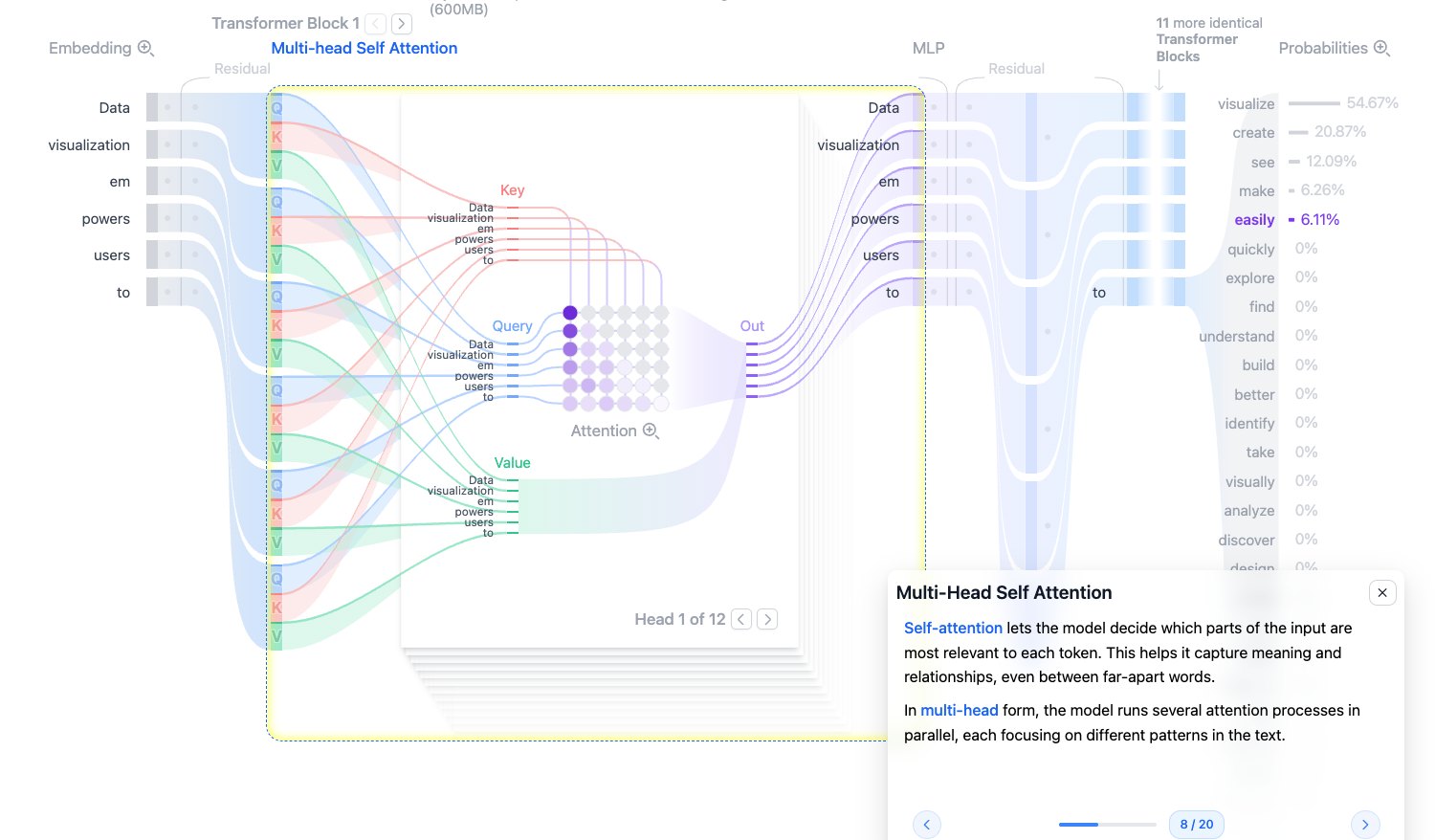
图源:Transformer Explainer
Query, Key, Value:Q、K、V 是什么
Self-Attention 会把每个 token 的输入向量分别映射成三个向量:
- Query (Q):当前 token 想查什么信息。
- Key (K):每个 token 能被别人匹配到的特征。
- Value (V):真正要被聚合传递的信息内容。
它们来自线性变换:
$$ Q = XW_Q,\quad K = XW_K,\quad V = XW_V $$一个通俗类比是搜索引擎:
- Query 是搜索词。
- Key 是网页标题或索引。
- Value 是网页正文内容。
先用 Query 和 Key 算相关性,再根据相关性加权读取 Value。
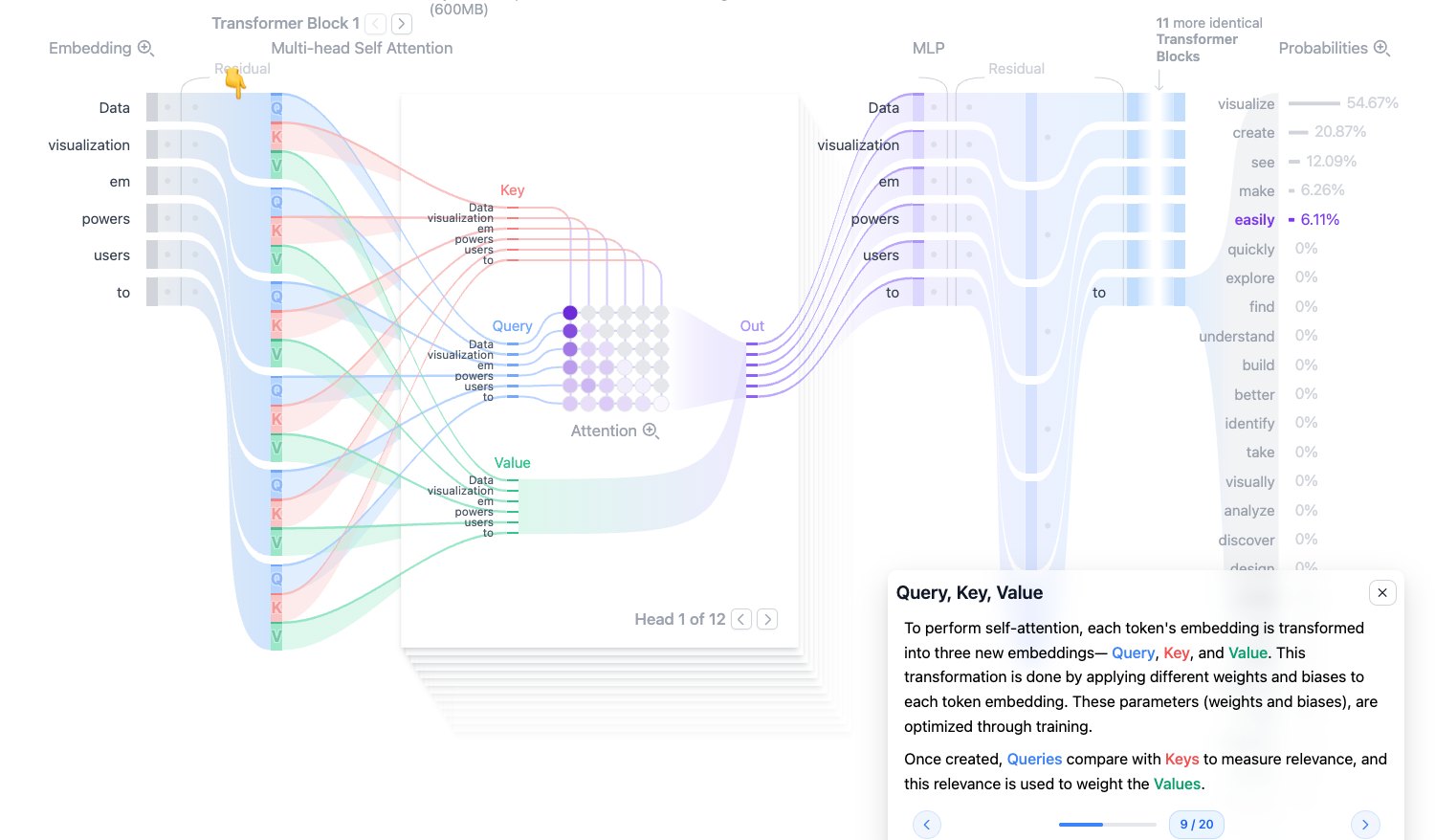
图源:Transformer Explainer
Multi-head:把 Q/K/V 切成多个头
GPT-2 small 的 embedding 维度是 768,attention head 数是 12,所以每个 head 处理的维度通常是:
$$ 768 / 12 = 64 $$多头机制的好处是并行学习多种关系。一个 head 可能关注相邻词,另一个 head 可能关注主谓关系,还有 head 可能关注更远处的语义提示。
多个 head 不是重复劳动,而是让模型拥有多个“观察角度”。
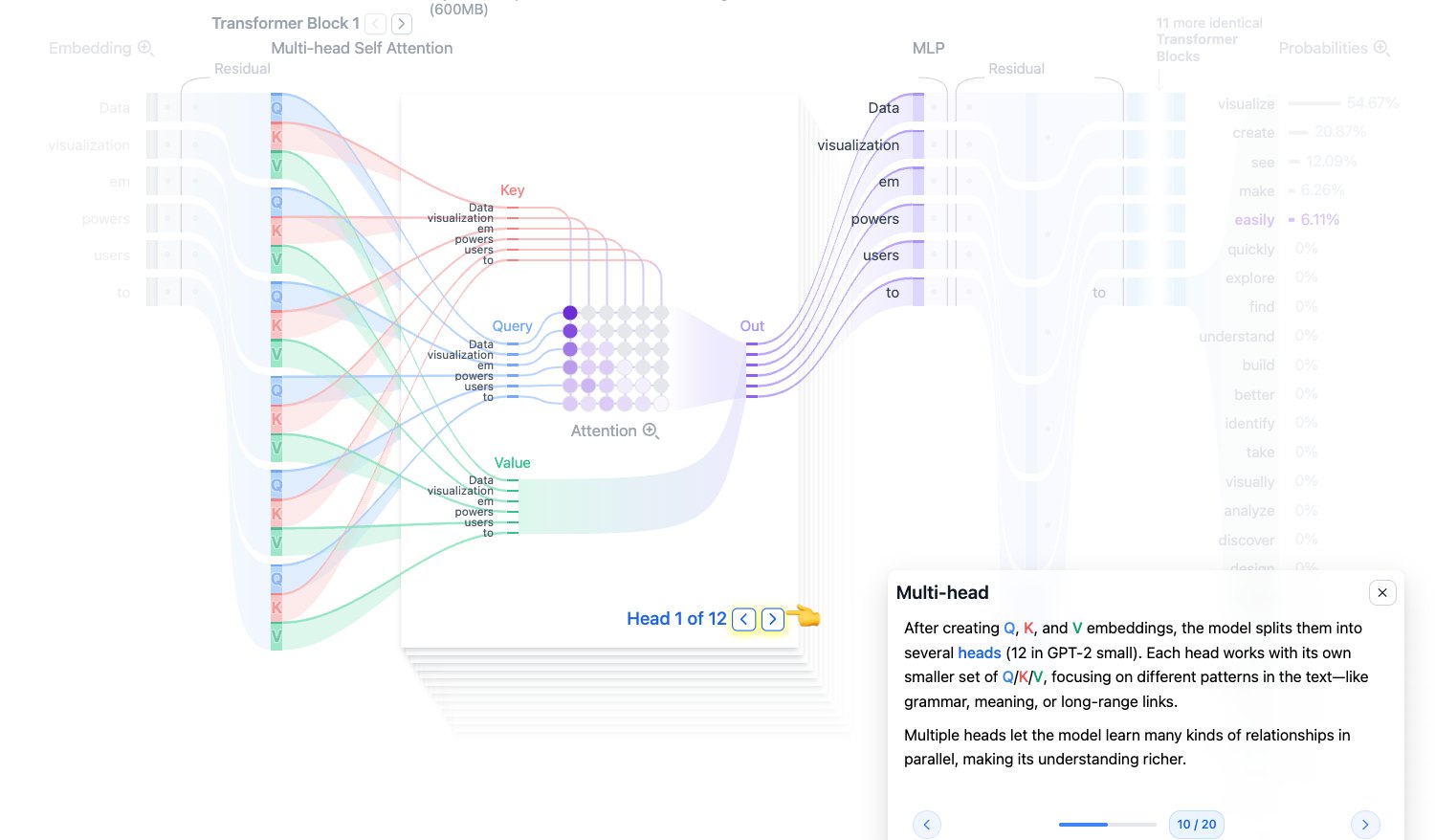
图源:Transformer Explainer
Masked Self Attention:带掩码的自注意力
GPT 这类模型是从左到右生成文本的。预测当前位置时,不能偷看未来 token,所以要使用 causal mask,也叫 masked self-attention。
核心计算公式是:
$$ \text{Attention}(Q,K,V)=\text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V $$其中:
- $QK^T$:计算 token 两两之间的相似度。
- $\sqrt{d_k}$:缩放因子,避免点积值过大导致 softmax 过尖。
- $M$:mask 矩阵,把未来位置设为 $-\infty$。
- softmax:把分数变成概率。
- 乘以 $V$:按注意力权重汇总信息。
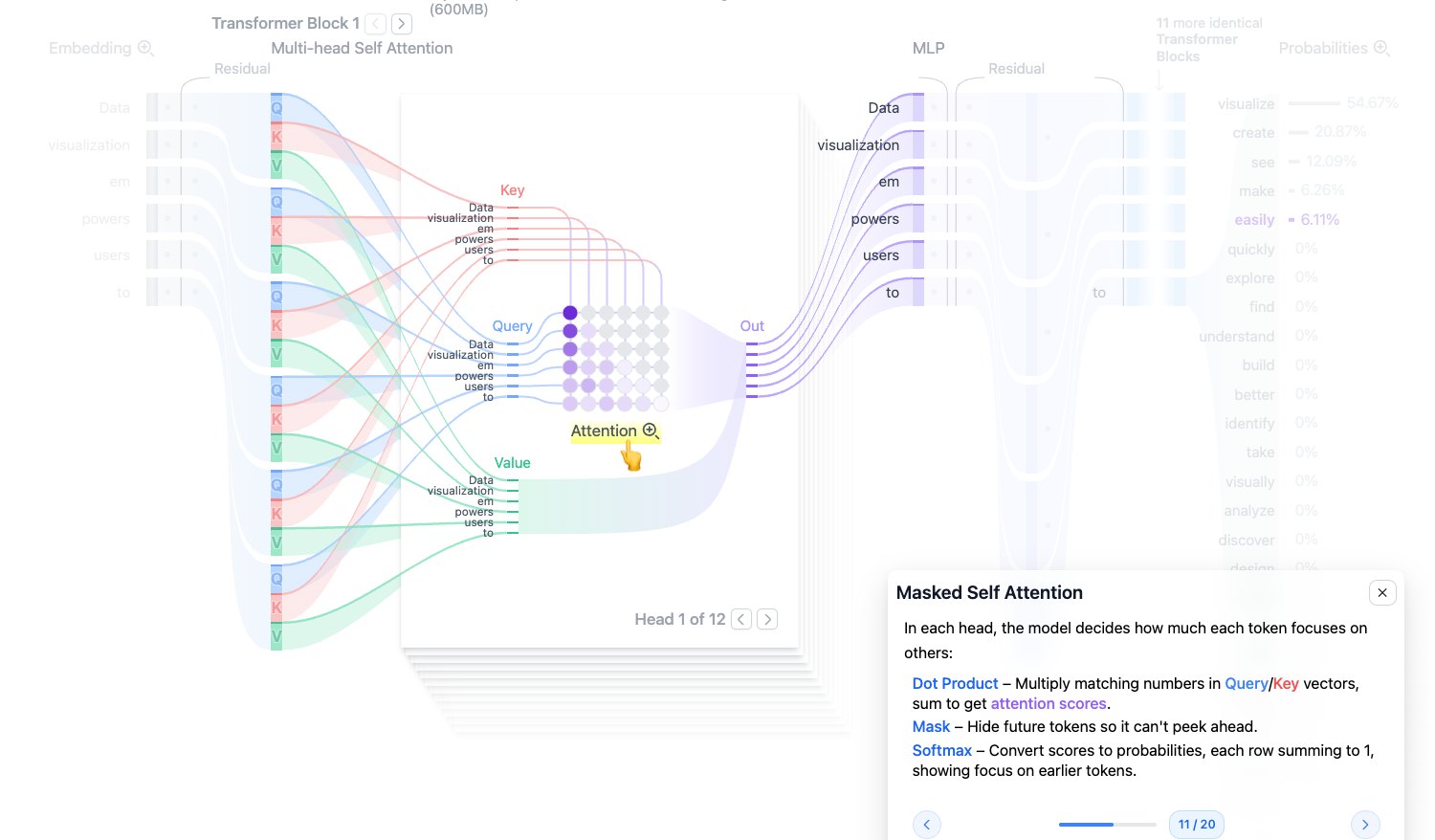
图源:Transformer Explainer
Attention Output & Concatenation:注意力输出与拼接
每个 head 都会输出一份上下文增强后的 token 表示。因为 GPT-2 small 有 12 个 head,所以会得到 12 份结果。
接下来模型会把这些 head 的输出拼接起来,再经过一次线性投影,回到原来的隐藏维度 768:
head_1, head_2, ..., head_12 -> concat -> linear projection
这一步的意义是:先让多个 head 分别提取信息,再把多种视角融合成一个统一表示。
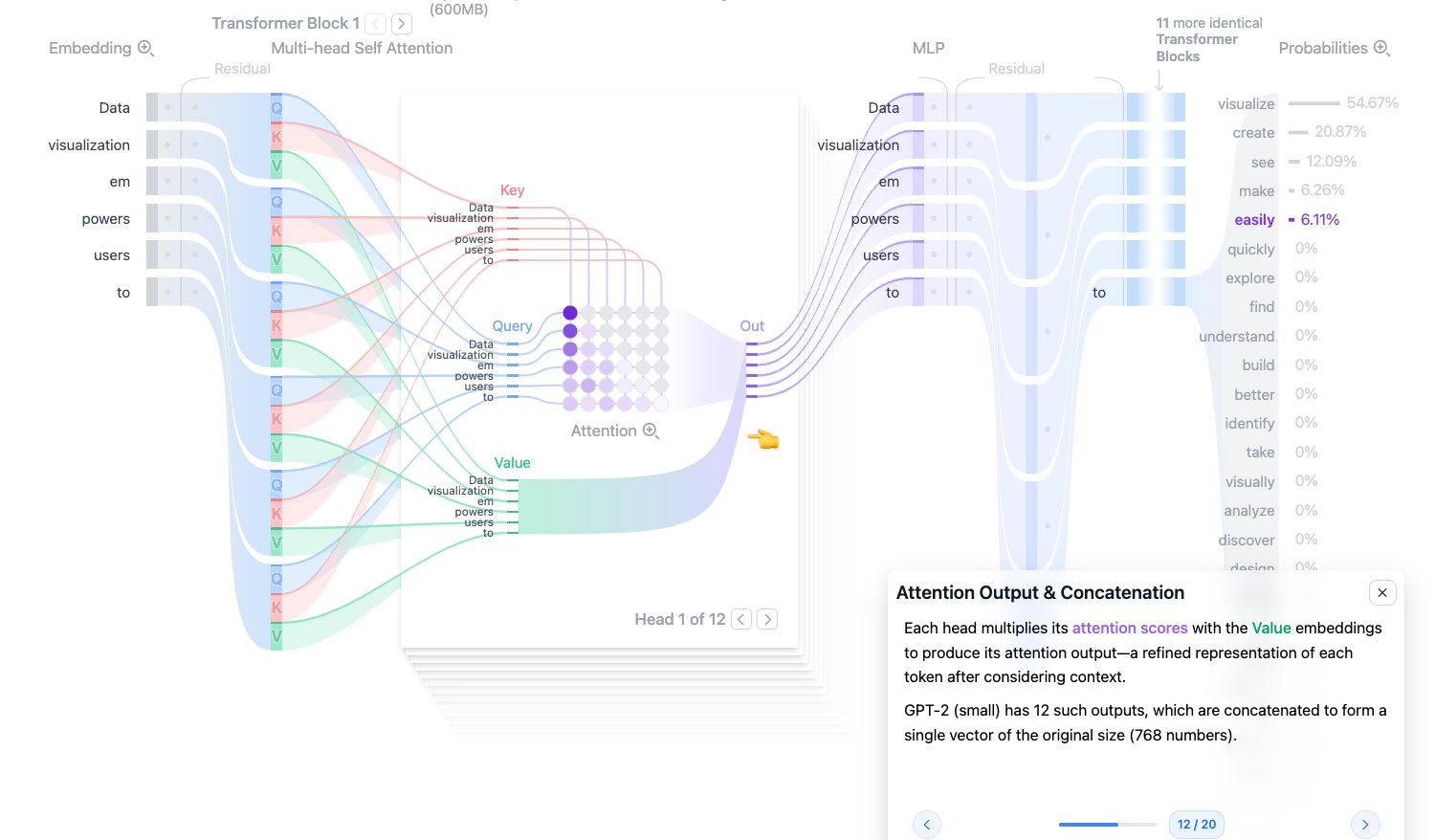
图源:Transformer Explainer
MLP:逐 token 的非线性加工
Attention 负责 token 之间的信息流动,MLP 负责对每个 token 自己的表示进行加工。
GPT-2 的 MLP 通常包含两层线性变换,中间接 GELU 激活:
$$ \text{MLP}(x)=W_2\cdot \text{GELU}(W_1x+b_1)+b_2 $$第一层会把维度从 768 扩展到 3072,第二层再压回 768。扩展维度可以让模型在更高维空间中表达更复杂的特征。
注意:MLP 不像 Attention 那样跨 token 交流信息,它是对每个 token 独立处理。
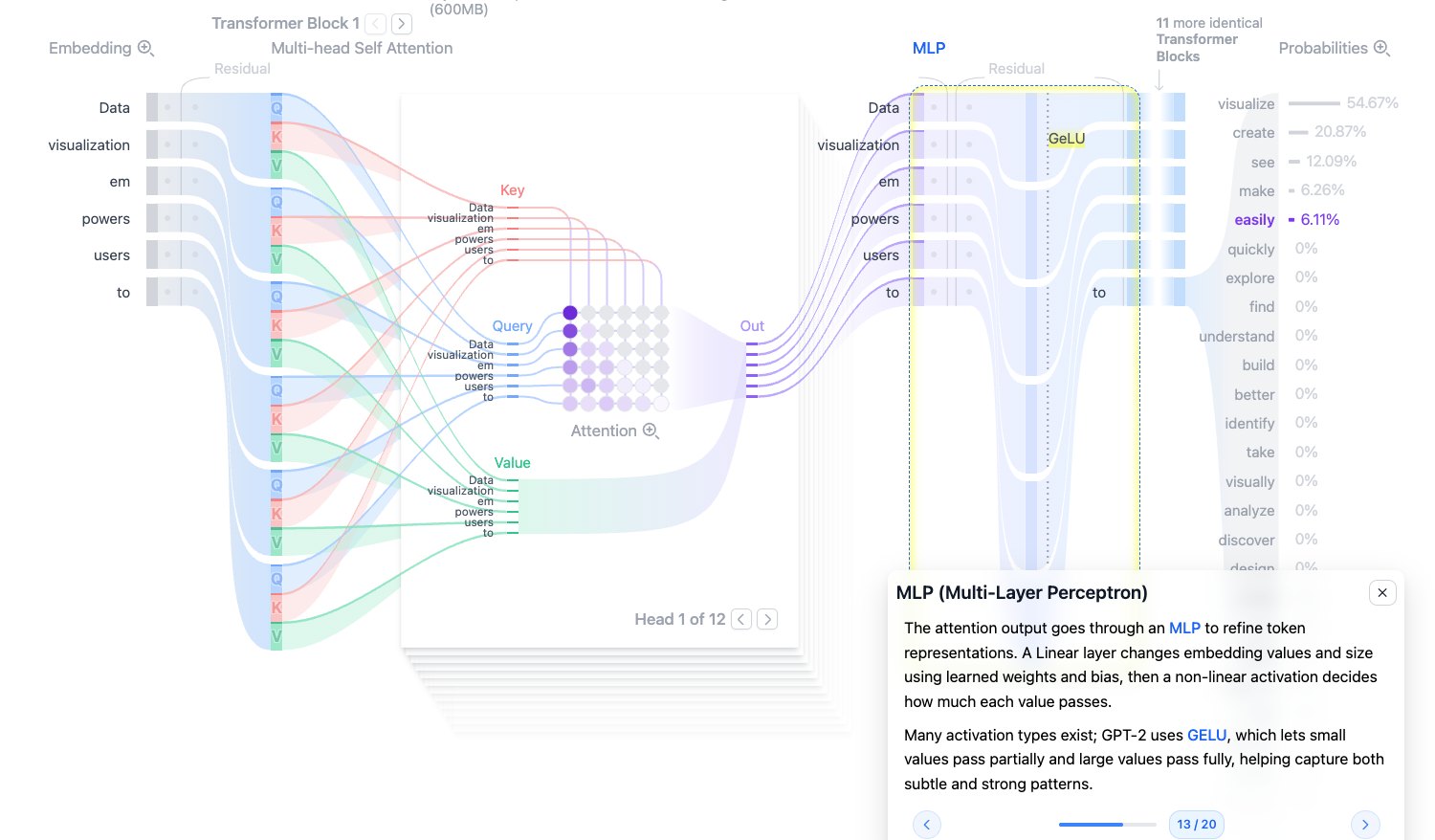
图源:Transformer Explainer
Output Logit:输出 logits
经过所有 Transformer Blocks 后,模型会拿最后一个位置的输出向量去预测下一个 token。
这个向量会经过最终线性层,映射到词表大小:
$$ \text{logits}=h_{\text{last}}W_{\text{vocab}}+b $$GPT-2 的词表大小是 50,257,所以 logits 是一个长度为 50,257 的向量。每个数对应一个候选 token 的原始分数。
logit 不是概率。它可以是任意实数,还需要经过 softmax 才能变成概率分布。
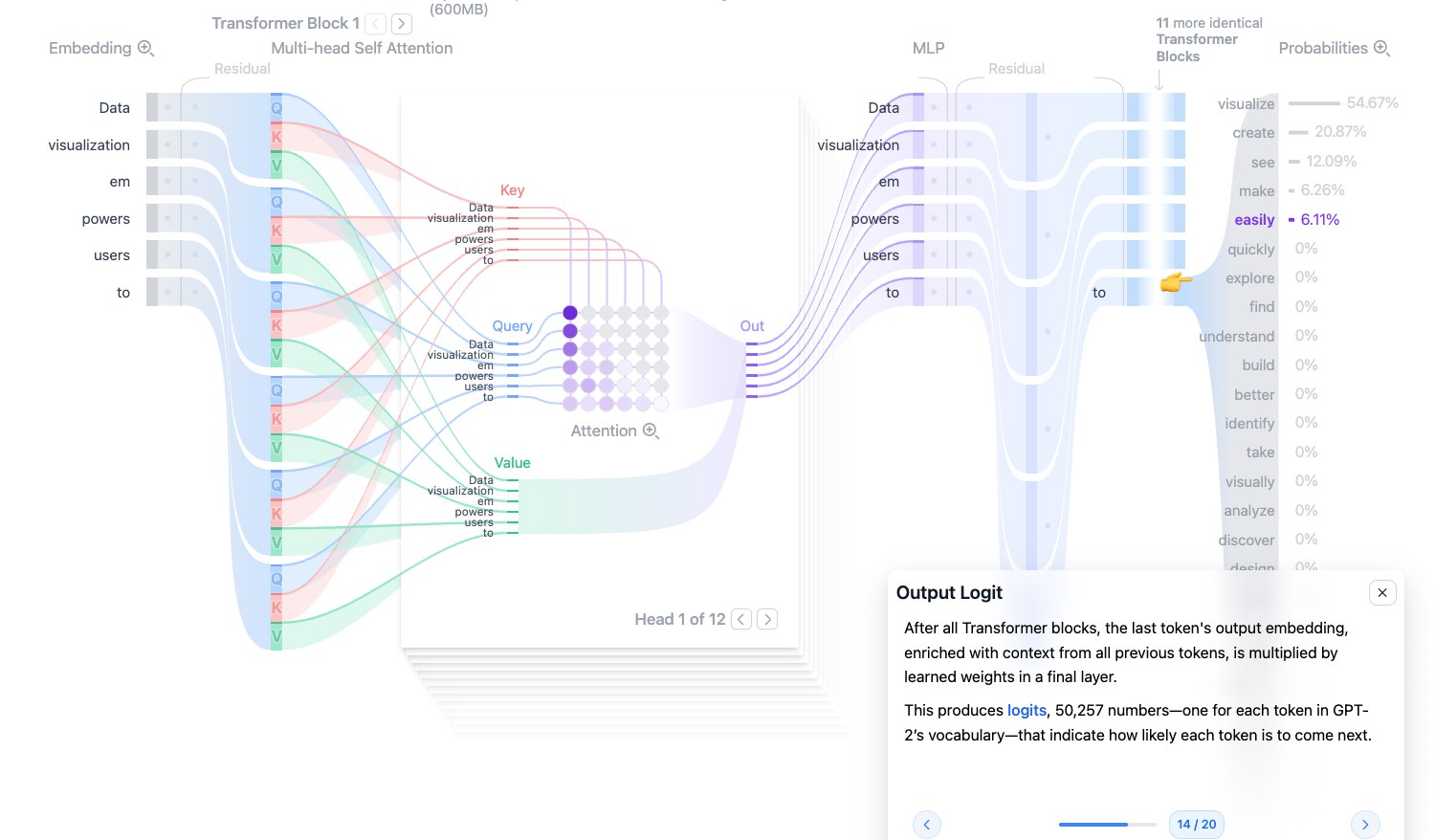
图源:Transformer Explainer
Probabilities:从 logits 到概率
Softmax 会把 logits 转换成概率:
$$ p_i=\frac{e^{z_i}}{\sum_j e^{z_j}} $$转换后有两个特点:
- 每个 token 的概率都在 0 到 1 之间。
- 所有 token 的概率加起来等于 1。
图中可以看到,示例输入后,模型认为 visualize、create、see、make 等 token 是比较可能的下一个 token。
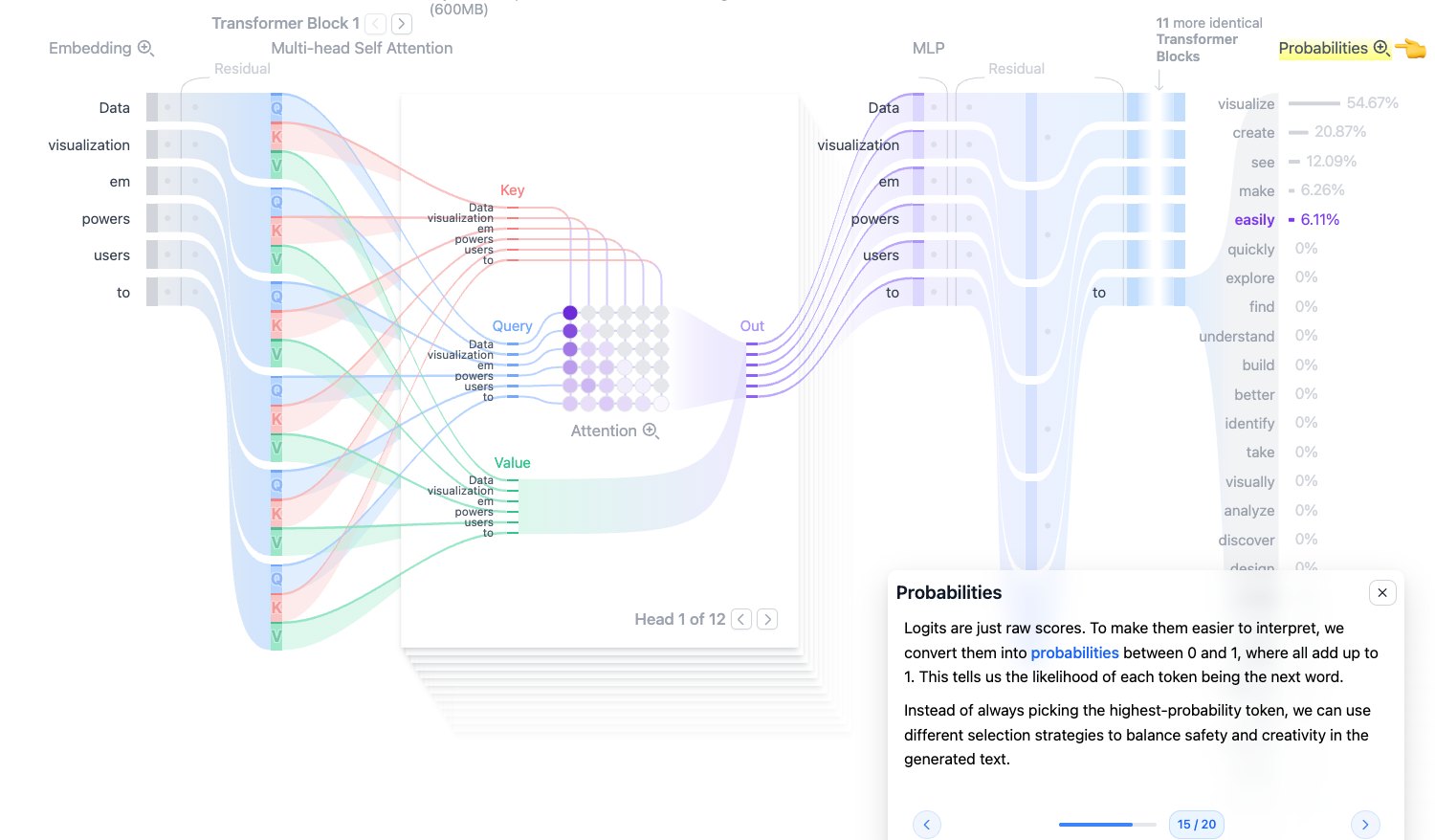
图源:Transformer Explainer
Temperature:温度控制生成随机性
Temperature 会在 softmax 前缩放 logits:
$$ p_i=\frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)} $$其中 $T$ 是 temperature:
- $T < 1$:概率分布更尖锐,高分 token 更容易被选中,输出更稳定。
- $T = 1$:不额外调整 logits。
- $T > 1$:概率分布更平坦,低概率 token 也有更多机会被选中,输出更多样。
通俗地说,temperature 越低越保守,越高越发散。
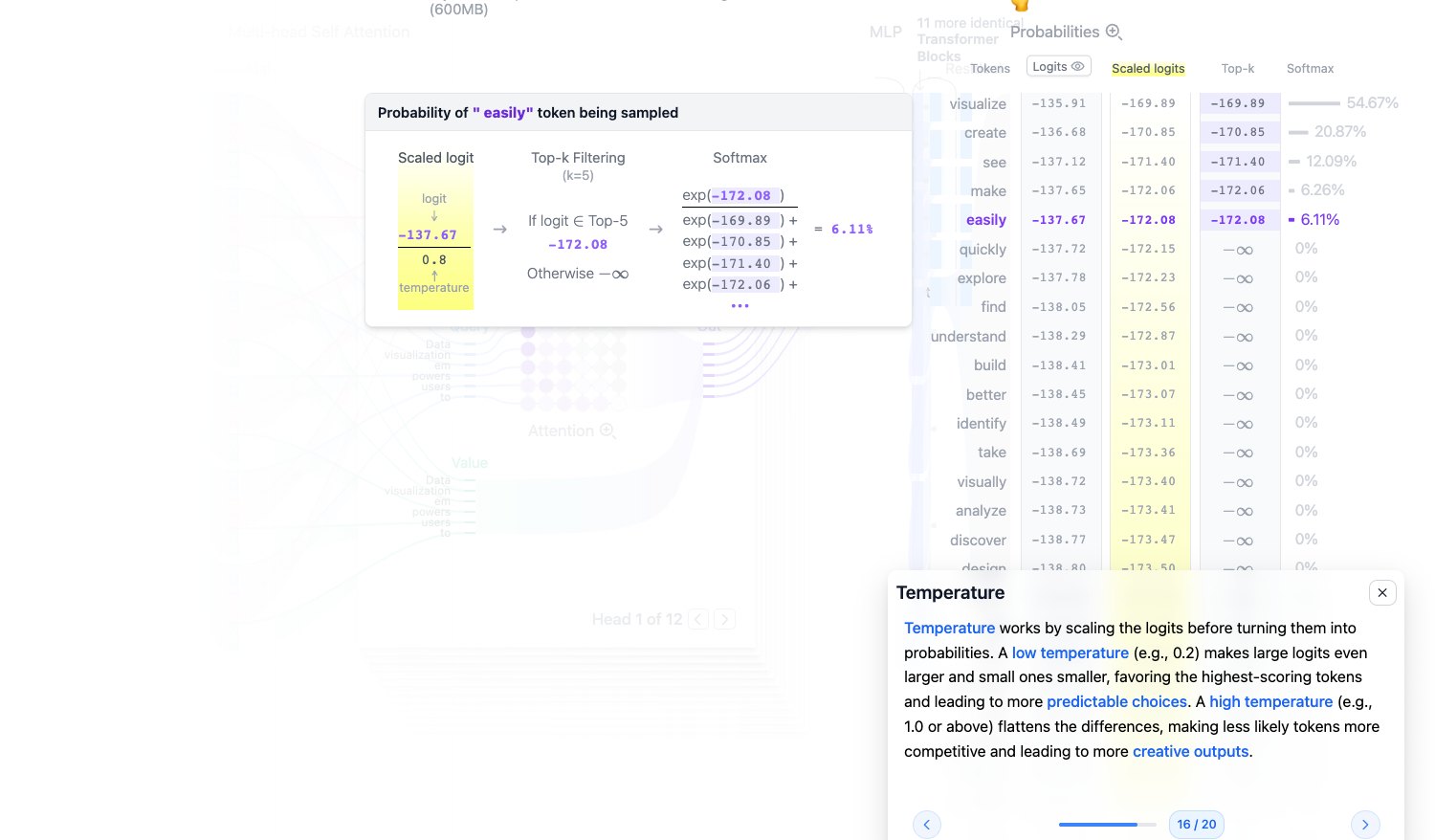
图源:Transformer Explainer
Sampling Strategy:采样策略
得到概率分布后,模型还要决定如何选下一个 token。常见策略有:
- Greedy Search:永远选概率最高的 token,稳定但容易死板。
- Top-k:只保留概率最高的 k 个 token,再从中采样。
- Top-p:保留累计概率达到 p 的最小 token 集合,也叫 nucleus sampling。
Top-k 更像固定候选池,Top-p 更像动态候选池。实际使用时,temperature 和 top-k/top-p 经常一起调。
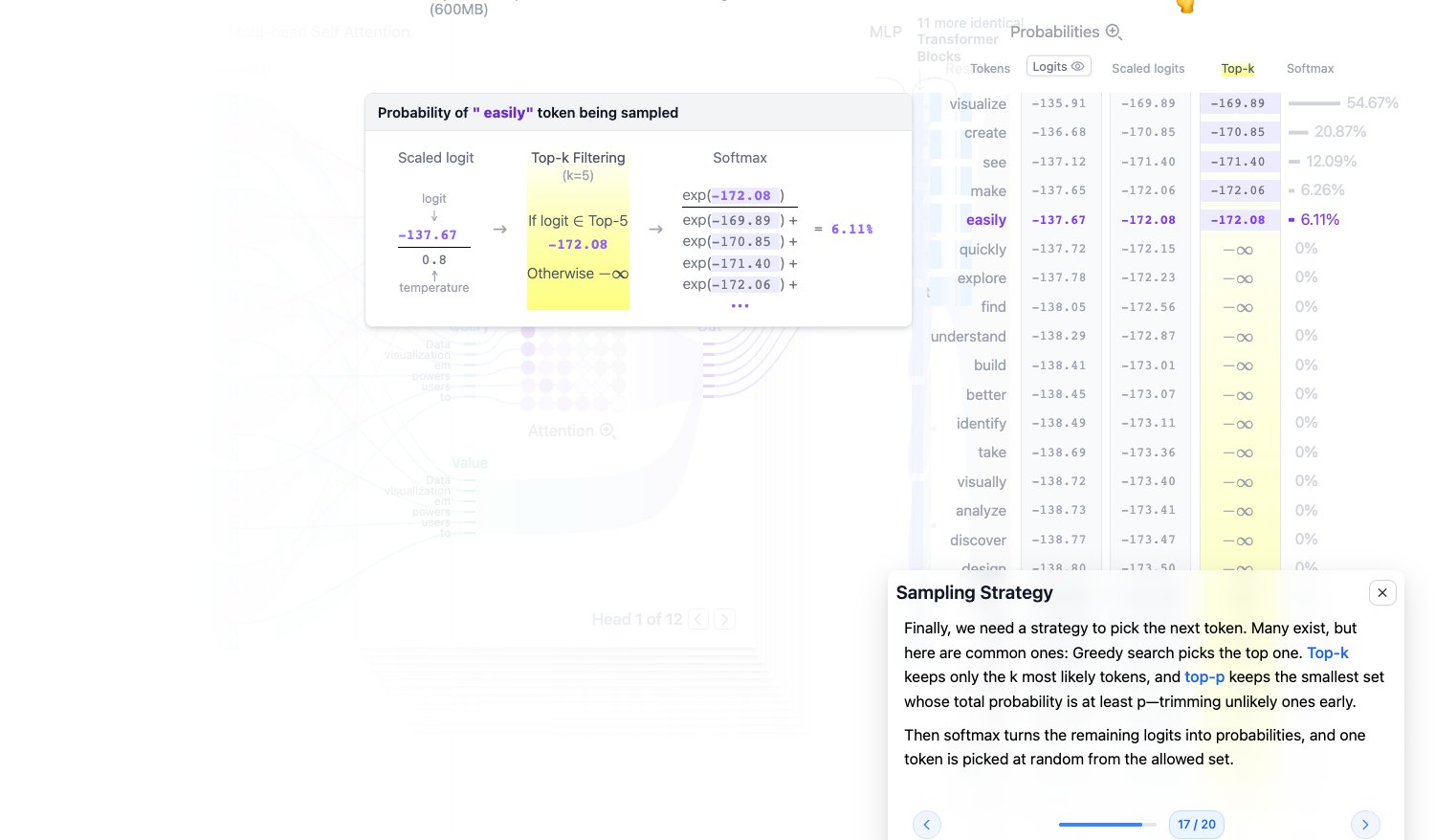
图源:Transformer Explainer
Residual Connection:残差连接
残差连接会把某一层的输入直接加到输出上:
$$ y = x + F(x) $$它的作用是保留原始信息,并让梯度更容易穿过深层网络。如果没有残差连接,模型层数很深时,训练会更困难,早期层的信息也更容易丢失。
在 Transformer 中,Attention 和 MLP 周围通常都有残差连接。
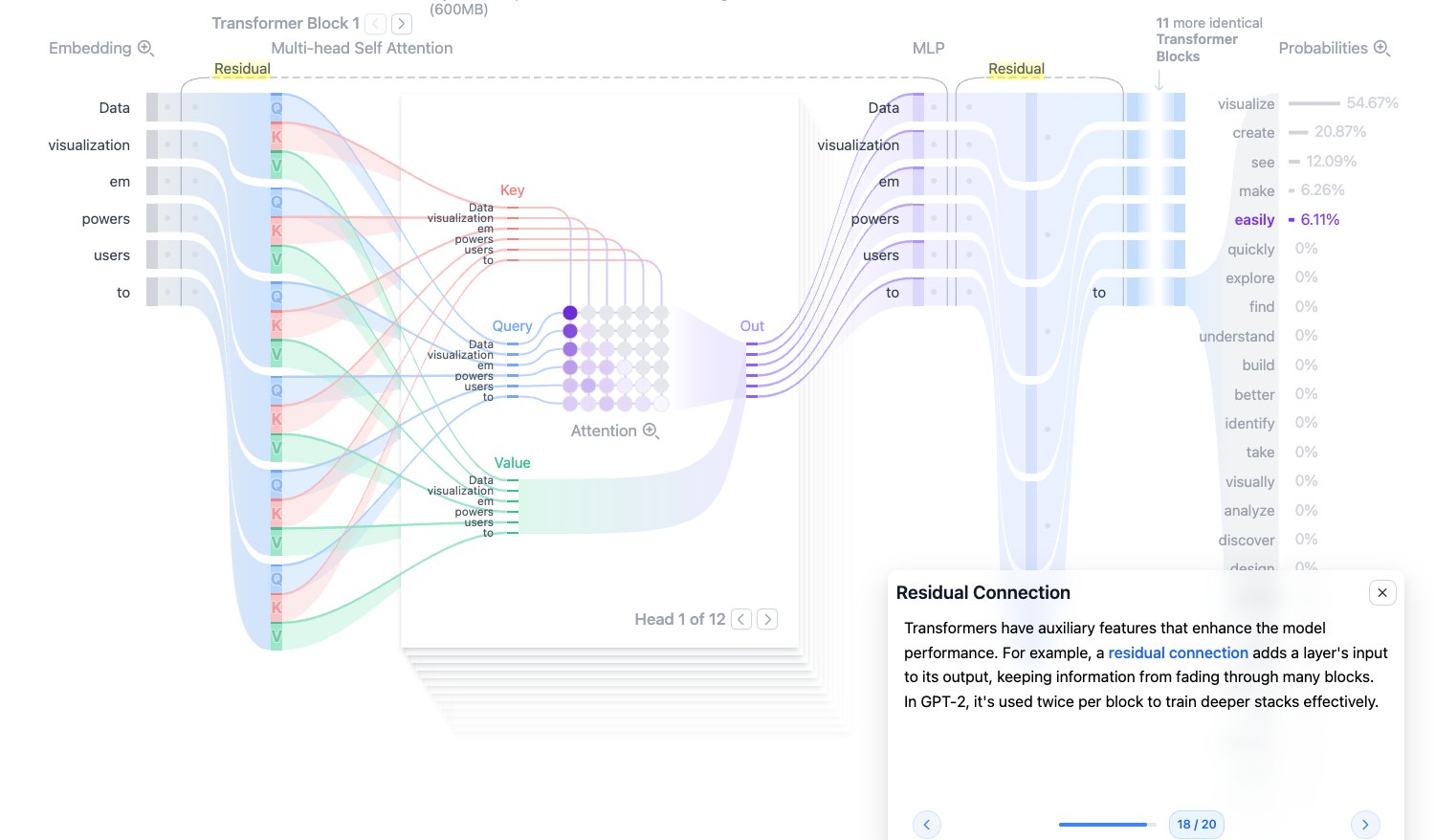
图源:Transformer Explainer
Layer Normalization:层归一化
Layer Normalization 会对一个 token 向量内部的数值做归一化,使均值和方差更稳定:
$$ \text{LayerNorm}(x)=\gamma\frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta $$它能减少训练不稳定,让每一层输入分布更可控。GPT-2 使用的是 pre-norm 风格:在进入 Attention 和 MLP 前先做 LayerNorm。
通俗理解:LayerNorm 像是在每次进入关键计算前,先把数值尺度整理到比较合适的范围。
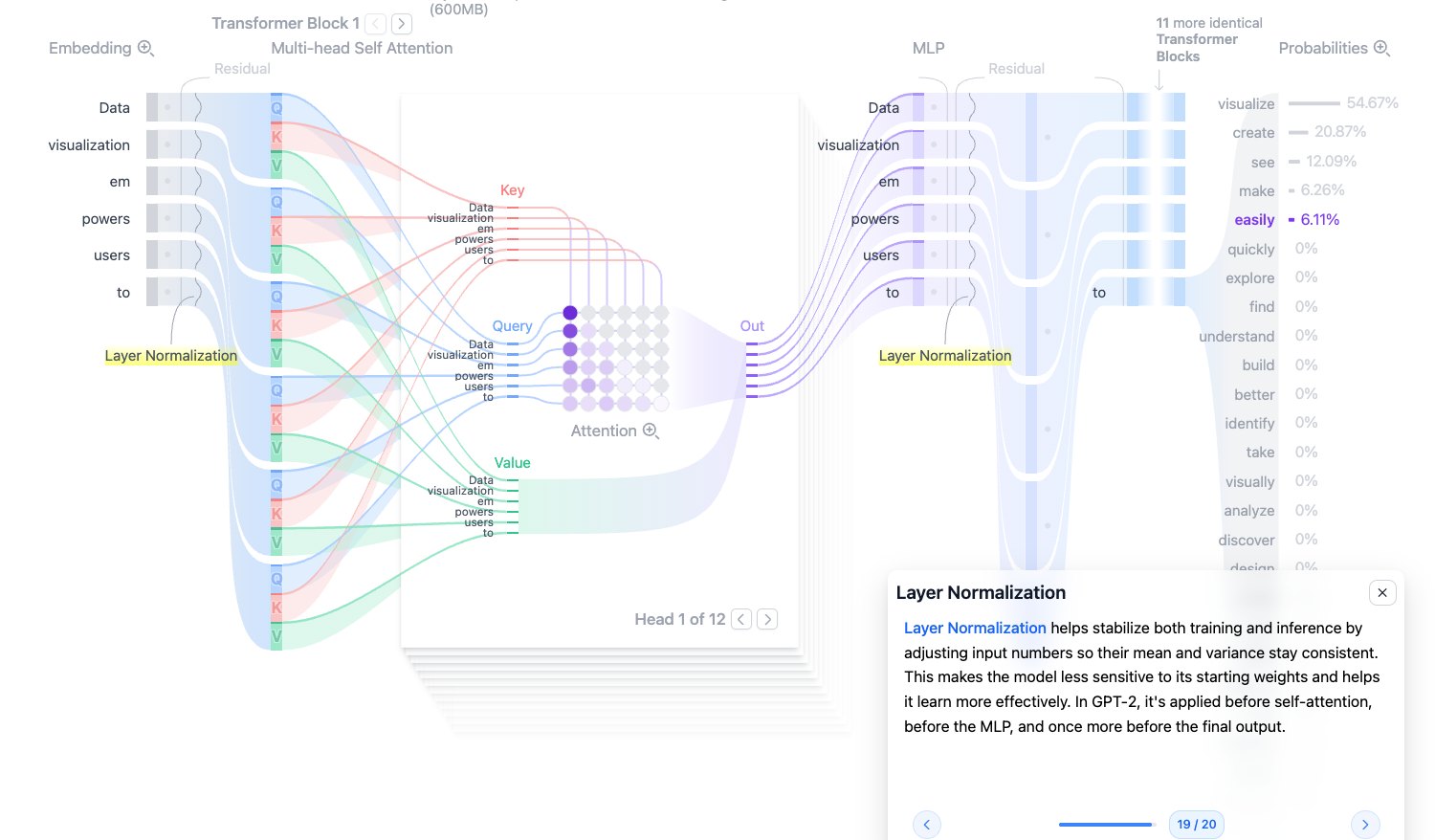
图源:Transformer Explainer
Dropout:训练时的随机失活
Dropout 是训练阶段的正则化方法,会随机把一部分连接或激活置零,避免模型过度依赖某些局部特征。
它的直觉是:训练时不要让模型每次都走完全相同的路径,迫使它学到更稳健的表示。
需要注意:
- Dropout 主要用于训练。
- 推理时 Dropout 会关闭。
- 很多新一代大模型因为训练数据极大,Dropout 使用得比早期模型更少。
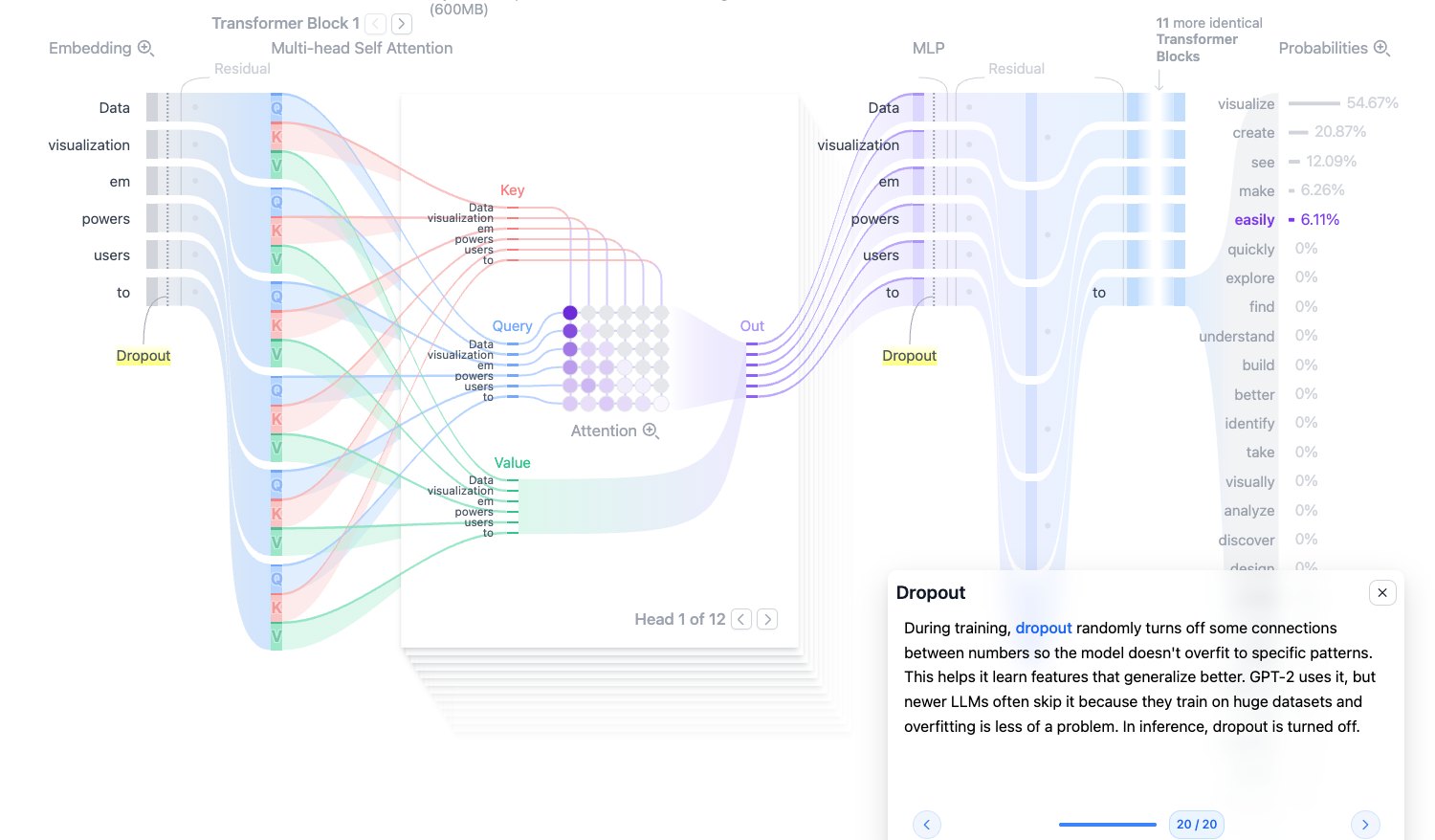
图源:Transformer Explainer
一张流程图总结
可以把 GPT 类 Transformer 的推理流程压缩成下面这条链路:
和 RNN 的关键区别
结合之前的 RNN 学习,可以这样理解二者差异:
| 对比点 | RNN | Transformer |
|---|---|---|
| 信息传递方式 | 依赖隐藏状态逐步传递 | Self-Attention 让 token 直接互相读取 |
| 并行能力 | 时间步依赖强,难并行 | 同层 token 可并行计算 |
| 长距离依赖 | 路径长,容易衰减 | 任意位置可直接建立联系 |
| 上下文表示 | 压缩进隐藏状态 | 显式保留整段 token 表示 |
| 大模型训练 | 扩展效率较差 | 更适合 GPU/TPU 大规模矩阵计算 |
这也是为什么现代 LLM 主流选择 Transformer:它不仅建模能力强,而且工程上更适合大规模预训练。