RNN 循环神经网络学习笔记
本文是学习 Andrej Karpathy 经典博客 The Unreasonable Effectiveness of Recurrent Neural Networks 时整理的中文笔记。原文发表于 2015 年,重点用字符级语言模型展示 RNN/LSTM 为什么能从原始文本中学到拼写、格式、结构、局部语法,甚至一些可解释的“状态记忆”。
这篇笔记的主线是:
- RNN 为什么适合处理序列
- RNN 的核心公式和计算过程
- 字符级语言模型如何训练与采样
- Karpathy 原文中的经典实验说明了什么
- 为什么后来 RNN 在主流 NLP 中被 Transformer 取代
RNN 解决什么问题
普通前馈神经网络通常假设输入和输出是固定长度的向量,例如输入一张图片,输出一个分类结果。但很多真实任务天然是序列:
- 文本:一句话由多个 token 或字符组成
- 语音:声音帧按时间排列
- 视频:画面帧按时间排列
- 翻译:输入一句话,输出另一种语言的一句话
- 生成任务:前面生成的内容会影响后面生成什么
RNN 的关键思想是:模型在处理当前输入时,不只看当前输入,还维护一个隐藏状态,用来压缩过去的上下文。
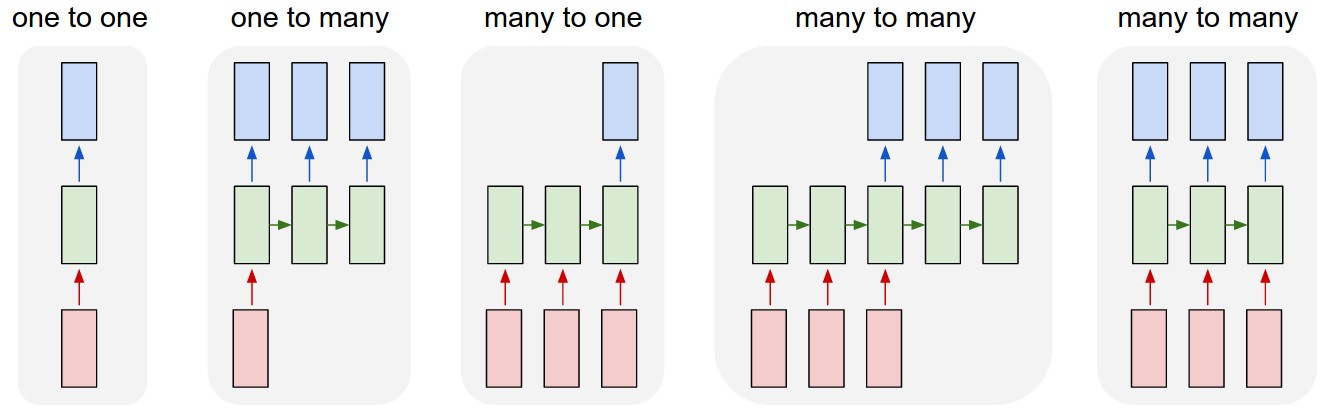
图源:Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks。红色表示输入,蓝色表示输出,绿色表示循环状态。它展示了固定输入输出、序列输出、序列输入、序列到序列、同步序列输入输出等常见模式。
可以把 RNN 理解成一个不断被调用的 step 函数:
rnn = RNN()
y = rnn.step(x)
每调用一次 step(x),RNN 会读取当前输入 x_t,结合之前的隐藏状态 h_{t-1},更新出新的隐藏状态 h_t,并产生当前输出 y_t。
Vanilla RNN 的核心公式
最基础的 RNN 更新公式是:
$$ h_t = \tanh(W_{hh}h_{t-1} + W_{xh}x_t + b_h) $$$$ y_t = W_{hy}h_t + b_y $$其中:
- $x_t$:第 $t$ 个时间步的输入
- $h_{t-1}$:上一个时间步的隐藏状态
- $h_t$:当前时间步的隐藏状态
- $W_{xh}$:输入到隐藏状态的权重
- $W_{hh}$:隐藏状态到隐藏状态的循环权重
- $W_{hy}$:隐藏状态到输出的权重
- $\tanh$:非线性激活函数,把值压到 $[-1, 1]$
对应到代码,大致是:
class RNN:
def step(self, x):
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
y = np.dot(self.W_hy, self.h)
return y
学习时最重要的是理解 h 的意义:它不是手写规则,而是模型在训练中自己学出来的“上下文摘要”。如果输入是文本,h 可能会携带当前是否在引号内、是否在 URL 内、某个括号是否已打开、前面出现了哪些词等信息。
为什么 RNN 可以建模上下文
以字符串 hello 为例。假设词表只有 h, e, l, o 四个字符,训练时输入可以是:
输入:h e l l
目标:e l l o
注意第一个 l 后面的目标是 l,第二个 l 后面的目标是 o。如果模型只看当前字符,两个时间步输入都一样,无法判断下一个字符应该是什么。RNN 必须利用隐藏状态记录“前面已经看到了什么”。
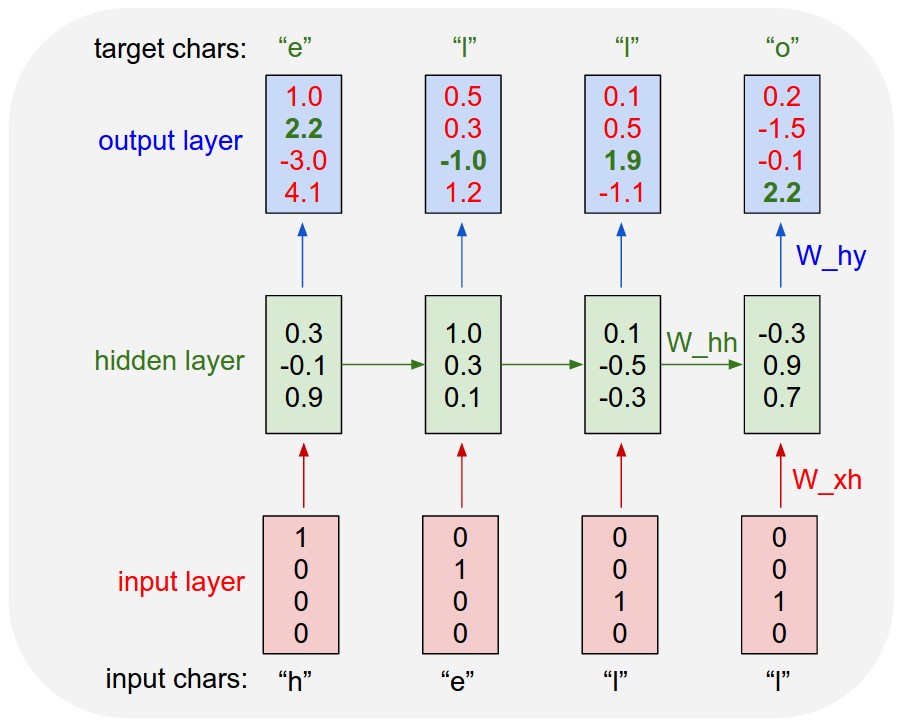
图源:Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks。图中模型逐字符读入 hell,每一步输出对下一个字符的打分,绿色目标表示希望模型提高的正确字符分数。
训练目标通常是每个时间步的交叉熵损失:
$$ \mathcal{L} = -\sum_t \log p(x_{t+1}\mid x_{\le t}) $$其中:
- $x_{\le t}$ 表示当前位置之前和当前位置的上下文
- $p(x_{t+1}\mid x_{\le t})$ 表示模型基于历史上下文预测下一个字符的概率
训练完成后,生成文本的流程是:
- 给模型一个起始字符或起始文本
- 得到下一个字符的概率分布
- 从分布里采样一个字符
- 把采样出的字符再喂回模型
- 重复以上过程
这就是字符级语言模型最朴素的生成方式。
BPTT:RNN 如何训练
RNN 每个时间步复用同一组参数。训练时会把循环结构按时间展开,然后做反向传播,这叫 Backpropagation Through Time, BPTT。
如果序列很长,完整展开会很贵,所以常用 Truncated BPTT,只往回传播固定长度。例如 Karpathy 原文的 Paul Graham 实验中使用了长度为 100 个字符的截断 BPTT。
RNN 训练的难点主要来自长链式梯度:
$$ \frac{\partial \mathcal{L}}{\partial h_{t-k}} $$需要经过很多次矩阵乘法和非线性函数。当链条很长时,梯度可能:
- 越传越小:梯度消失,模型难以学习长期依赖
- 越传越大:梯度爆炸,训练不稳定
这也是后来 LSTM、GRU 被大量使用的原因。
LSTM:更强的循环单元
Karpathy 原文里的实验实际使用的是 LSTM。LSTM 仍然属于 RNN 家族,但它把隐藏状态更新设计得更复杂,引入门控机制,让模型更容易保留或遗忘信息。
LSTM 的典型组件包括:
- 遗忘门:决定旧信息保留多少
- 输入门:决定新信息写入多少
- 输出门:决定当前状态暴露给输出多少
- 细胞状态:提供更稳定的信息通道
直觉上,Vanilla RNN 每一步都把旧状态和新输入混在一起重新压缩,长期信息很容易被覆盖;LSTM 给模型提供了“写入、保留、读取”的机制,所以更适合长序列。
Karpathy 原文中的经典实验
模型从字符中学会结构
原文展示了把 RNN/LSTM 训练在不同文本上的效果,包括:
- Paul Graham 文章
- Shakespeare 剧本
- Wikipedia Markdown/XML
- 代数几何 LaTeX
- Linux 源码
- 婴儿名字列表
这些实验的共同点是:模型没有显式的词典、语法规则、Markdown 规则、XML 树规则或 C 语言规则,只是在做“预测下一个字符”。但训练后,它能生成看起来像原数据分布的内容。
这说明:下一个字符预测看似简单,实际会倒逼模型学习多层结构。
- 字符层:拼写、空格、标点
- 词层:常见词、名字、变量名
- 句法层:引号、括号、缩进、标签闭合
- 风格层:莎士比亚式台词、维基百科式条目、源码注释
训练过程中的能力演化
Karpathy 用《战争与和平》做例子,展示了采样文本随训练迭代逐步变化:
- 早期:几乎是随机字符,但开始出现空格
- 中期:出现短词、句号、引号等局部结构
- 后期:出现更像英文的单词、名字和句子形式
这给我的理解是:RNN 不是一下子学会“语言”,而是先学最局部、最高频的模式,再逐渐形成更长范围的依赖。
隐藏单元学出了可解释状态
原文最经典的部分之一,是可视化 LSTM 隐藏单元的激活。某些神经元会在 URL 内激活,某些会在 [[...]] 这类 Markdown 链接环境中激活,还有一些神经元像是在跟踪引号区域。
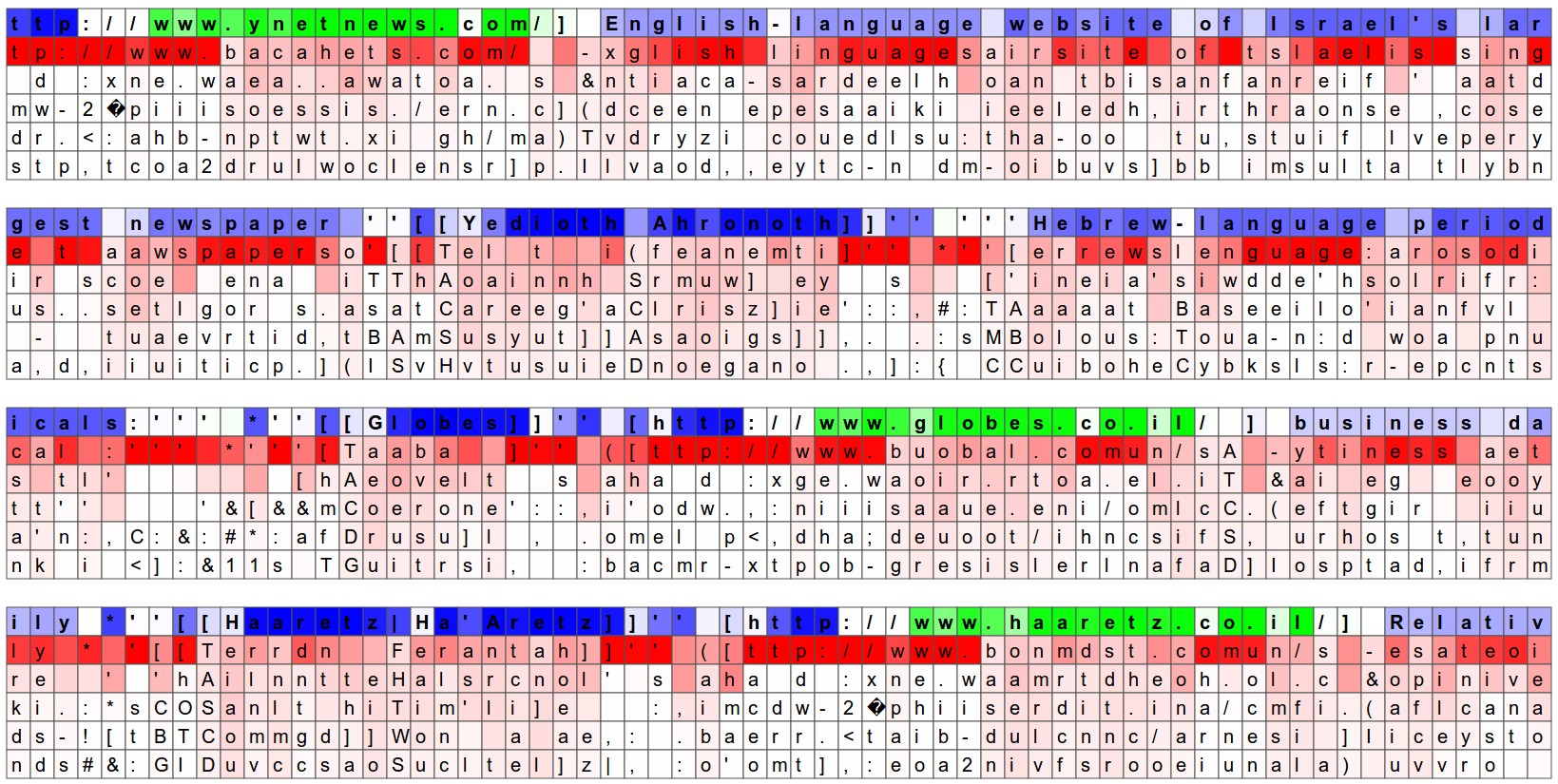
图源:Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks。该图展示了一个隐藏单元在 URL 区域明显激活,说明模型可能学到了“当前是否处在 URL 中”的内部状态。
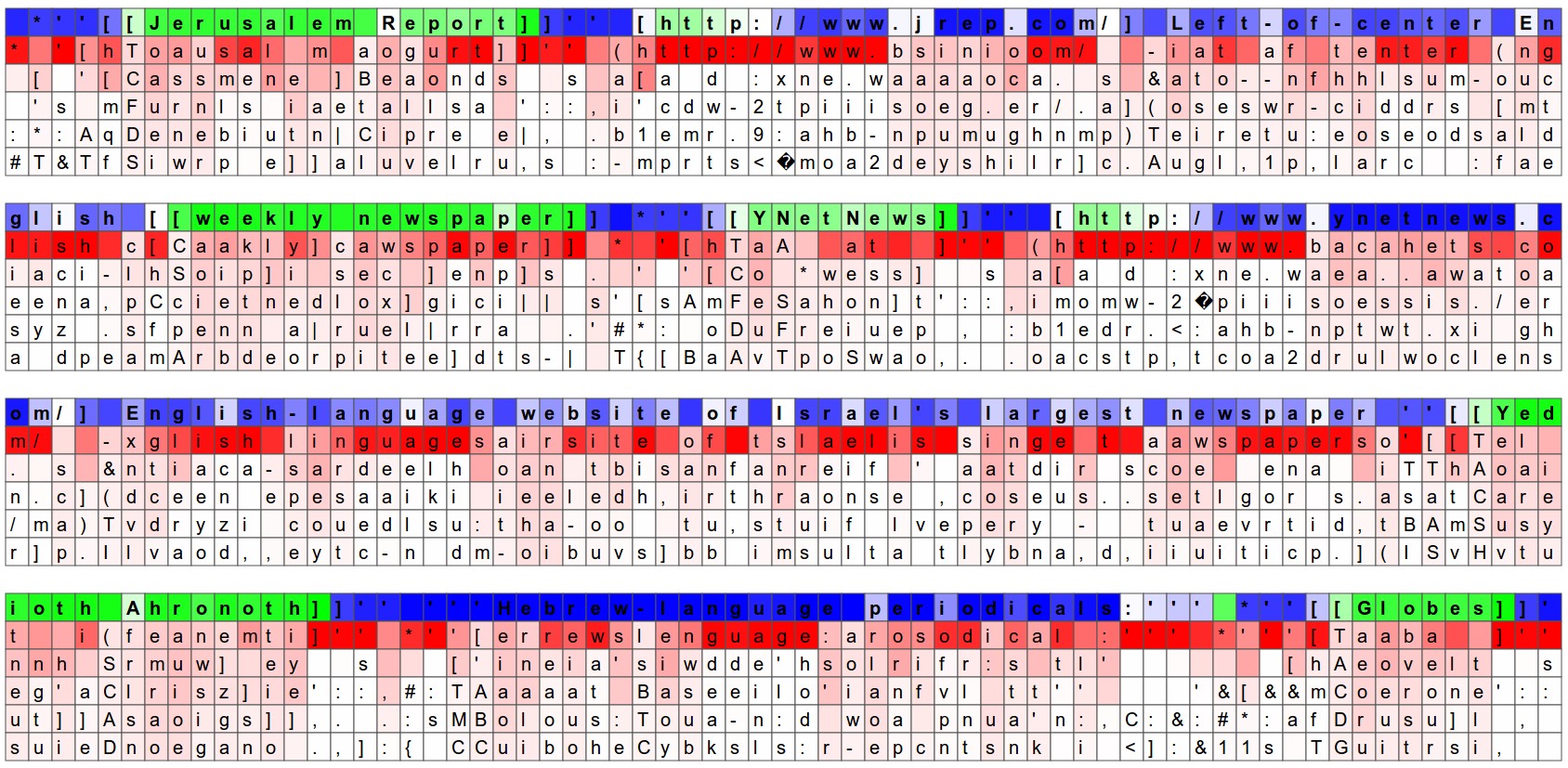
图源:Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks。该图展示了隐藏单元对 [[...]] Markdown 环境的响应。
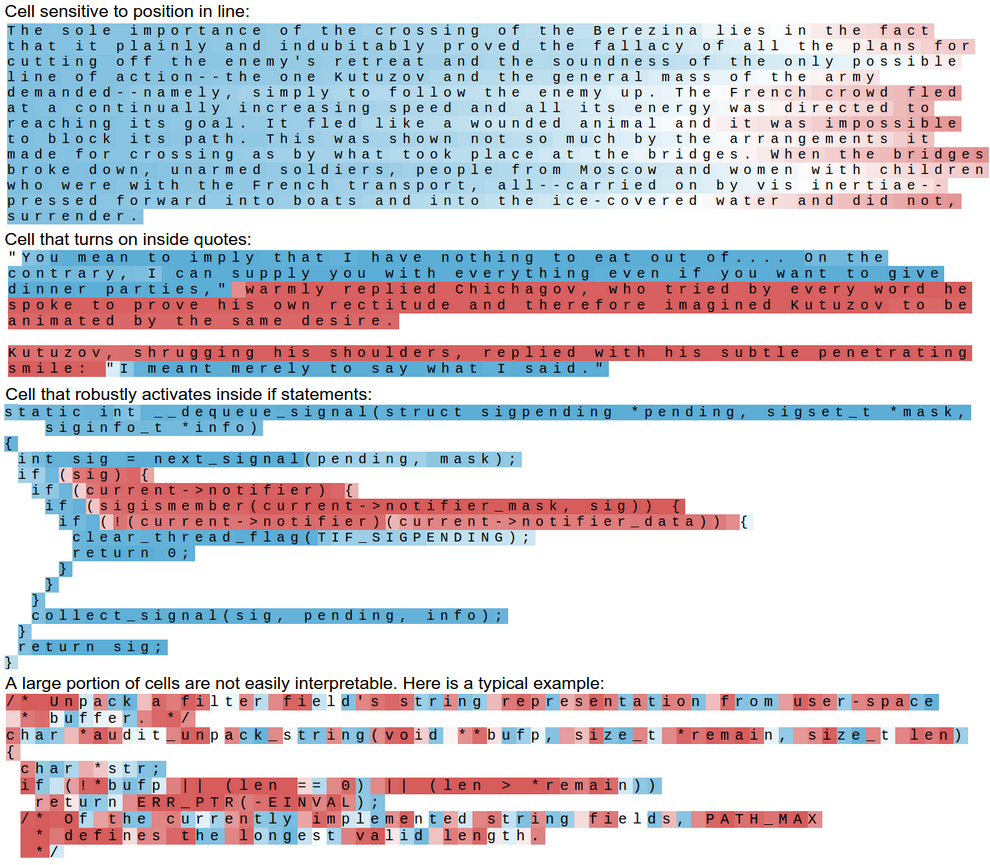
图源:Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks。这类可视化说明,一部分隐藏单元会学出人类可以解释的状态检测功能。
这里的重点不是说每个神经元都有明确语义,而是说明端到端训练可以让模型自己发现对任务有用的中间状态。对于“预测下一个字符”来说,知道自己是否在 URL、括号、引号中,确实会提高预测准确率。
RNN 也能处理非传统序列任务
Karpathy 原文还提到,即使数据本身不是序列,也可以把处理过程设计成序列。例如模型可以一步步移动注意力读取图片,或者一步步在画布上生成图像。

图源:Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks。左图相关实验来自 Recurrent Models of Visual Attention。

图源:Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks。右图相关实验来自 DRAW: A Recurrent Neural Network For Image Generation。
这给了一个重要视角:RNN 不只是“处理序列数据”,也可以表示“顺序执行的计算过程”。
采样温度:生成结果为什么会变
字符级语言模型输出的是下一个字符的概率分布。采样时常用温度系数调整分布:
$$ p_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)} $$其中:
- $z_i$ 是第 $i$ 个字符的 logit
- $T$ 是温度
温度的影响:
- $T < 1$:分布更尖锐,模型更保守,更容易重复高概率模式
- $T = 1$:正常采样
- $T > 1$:分布更平坦,输出更多样,但错误也更多
所以生成模型的“创造性”和“稳定性”经常是一个权衡。
RNN 的优点
RNN 的优势可以概括为:
- 天然适合流式输入:数据一个时间步一个时间步到来时,RNN 可以持续更新状态
- 参数共享:同一个
step函数复用在任意长度序列上 - 状态压缩:隐藏状态可以作为过去上下文的摘要
- 生成直觉简单:预测下一个 token,再把输出喂回模型
- 对小模型和特定时序任务仍有价值:例如传感器序列、实时语音、边缘设备上的低延迟任务
RNN 的局限
RNN 的主要问题也很清楚:
序列计算难并行
RNN 必须先算出 $h_{t-1}$,才能计算 $h_t$。这意味着一个序列内部的时间步很难完全并行。
对于短序列影响不大,但在大规模语言模型训练中,数据量和模型规模都很大,无法充分利用 GPU/TPU 并行能力会成为核心瓶颈。
长距离依赖困难
理论上,隐藏状态可以携带所有历史信息;实践中,固定长度的向量很难无损压缩长上下文。越早的信息经过越多次状态更新,越容易被覆盖或衰减。
LSTM/GRU 缓解了这个问题,但没有彻底解决。
信息通路太长
如果第 1 个 token 要影响第 1000 个 token,RNN 的信息需要穿过约 1000 次递归更新。路径越长,优化越难,信息越容易损失。
9.4 隐藏状态是瓶颈
RNN 把过去压缩进一个隐藏向量。这个向量既要存储上下文,又要参与下一步计算。Karpathy 原文在展望部分也提到,RNN 会把表示容量和每步计算量耦合在一起:隐藏状态越大,每一步矩阵乘法成本越高。
为什么 RNN 被 Transformer 取代
Transformer 不是因为“RNN 完全没用”才取代它,而是因为在大规模 NLP 任务上,Transformer 的工程特性和建模能力更适合扩展。
Transformer 更容易并行训练
RNN 按时间步递推:
$$ h_t = f(h_{t-1}, x_t) $$Transformer 的 self-attention 可以在同一层里同时计算序列中所有位置之间的关系。训练时,一个 batch 内的 token 表示可以大量矩阵化并行。
这正是 Attention Is All You Need 的核心动机之一:去掉 recurrence 和 convolution,仅使用 attention 构建序列转导模型,从而提高并行化程度并减少训练时间。
长距离依赖路径更短
在 RNN 中,远距离 token 之间的信息需要经过很多时间步传递。Transformer 的 self-attention 让任意两个位置可以在一层内直接建立联系。
可以粗略对比:
| 模型 | 两个远距离 token 的信息路径 |
|---|---|
| RNN | $O(n)$ |
| CNN | 取决于卷积层数和感受野 |
| Transformer self-attention | $O(1)$ |
路径更短通常意味着更容易学习长距离依赖。
Attention 显式访问上下文
RNN 依赖隐藏状态压缩历史,而 Transformer 的 attention 会为当前位置动态读取其它位置的信息:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$这相当于让模型在生成每个表示时,直接根据相关性从上下文中取信息,而不是完全依赖一个递推压缩状态。
Transformer 更符合大模型扩展规律
现代大语言模型依赖大数据、大参数、大算力。Transformer 的矩阵乘法密集、并行友好,能更好地吃满硬件;RNN 的时间步依赖限制了吞吐。
所以在大规模预训练语言模型时代,Transformer 的优势不仅是算法效果,也包括硬件效率、训练稳定性、生态工具和可扩展性。
10.5 但 RNN 没有完全消失
RNN 在一些场景仍有价值:
- 流式推理:输入持续到来,不想反复重算全部上下文
- 低延迟边缘任务:小模型、固定状态、推理成本可控
- 时间序列任务:某些传感器或控制任务不一定需要完整 self-attention
- 新架构研究:一些状态空间模型、线性注意力、RWKV 类模型又重新吸收了 recurrence 的思想
所以更准确的说法是:Transformer 在主流 NLP 和大模型训练中取代了传统 RNN/LSTM,但“循环状态”这个思想仍然在很多新架构中继续存在。
学习小结
RNN 的核心不是复杂公式,而是一个简单但强大的抽象:用同一个函数反复处理序列,并用隐藏状态携带过去的信息。
Karpathy 的文章经典之处在于,它没有先堆很多理论,而是用字符级生成实验说明:只要训练目标设计得足够通用,模型会为了完成预测任务,自发学到拼写、格式、括号、引号、URL、代码结构等多层模式。
但 RNN 的递推结构也决定了它在大规模训练中有天然瓶颈:难并行、长依赖难优化、隐藏状态压缩能力有限。Transformer 通过 self-attention 让序列位置之间直接交互,并大幅提升并行训练能力,因此成为现代 NLP 和大语言模型的主流架构。
学习来源
- Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks, 2015-05-21
- Andrej Karpathy, char-rnn GitHub repository
- Andrej Karpathy, Minimal character-level language model with a Vanilla Recurrent Neural Network, in Python/numpy
- Ashish Vaswani et al., Attention Is All You Need, 2017